之前给自己定过一个3年左右的计划,原因很简单,不管什么上天还是入地的公司,对我来说无非就是一个打工的地方而已;随时也要做好被公司用完就丢的准备。
既然到了所谓就业歧视年龄线,那就应该拿出一定的所谓能力来,不是技术上有一些自己可以落地的时间,就是管理上有很强的的软实力。
目前来说,进入管理通道之前,该有的技术实践还是需要跟上,后续想走资源受限场景下的卡顿、画质方向的优化,所以对网络和编解码相关有一个感性到浅层的了解时必须的。
为了了解编解码,为了不受到一些所谓的技术专家和算法专家的歧视,业余时间自己倒腾一个码流分析工具,同时也是为了自己可以用。
目前是ffmpeg + duilib来做的,首先我想当排斥做界面,一方面我自己不感兴趣,另一方面这东西要做深门槛很高,奈何这玩意入门门槛太低,庄家太多受不了这种乌烟瘴气的环境。
用ffmpeg来做码流处理,主要是因为解码器开源,可以看到代码也能试着去按照自己的需求改,另一个确实什么更快又更好的选择。
目前完成的功能有:
支持264 简单解析nalu 解码出码流 拿到运动适量 fuck ui绘制(用了ffmpeg的codecview来绘制运动适量) 接下来要做的功能:
拿到qp 拿到参考信息,帧级,块级 vui信息解析 后续需要完成的功能:
性能优化(优先级最低,除非出现不可忍受的情况) 残差图 频域图 支持265 自动化诊断码流(等其他功能差不多再说,这个需要大量实践经验,还需要了解vui)
前言
2022的计划,就是开始做个小工具,拿来分析es流,主要通过解码器解码es流,来获取编码中一些过程,比如预测方向,slice qp等等。当然也包括最基本的parser,虽然这块会有很多bug(只要是字节流相关的代码都很容易出现解析和打包问题)
所以现在最先需要解决的是ffmpeg的编译,然后再找一个稳定简易的界面库来先基本完成264的码流解析和解码工作。
脚手架选择
windows terminal
msys2
vs 2017
安装
略过
编译
配置
windows terminal
msys2
这里需要说明的是,msys2现在支持ucrt和mingw64两种链接方式,区别在于前者使用系统自带的crt链接到编译出来的库中,后者使用msvs的。目前还是继续使用mingw64的版本
#先更新一下
pacman -Syu
#库管理工具
pacman -S pkgconf diffutils
pacman -S make
#sdl2必须品
pacman -S mingw-w64-x86_64-nasm mingw-w64-x86_64-gcc mingw-w64-x86_64-toolchainvs 2017
略
其他
关于ffplay的编译
由于msys2自带的sdl2包和本地vs编译环境可能存在一些不兼容的情况,所以有两种办法。所以需要单独下载sdl2编译后,再创建ffplay的vs工程来做。
虽然我一直都是将自身技能分为软技能和硬技能,并且按照一定规则来进行计划,不过还是有必要重新考虑一下侧重点,这么几年下年,折腾来折腾去,东搞搞西弄弄,一直没有很好的执行一个系统性或者专业化的自身知识技能体系。但维度有一点很明确的是,自身工作方向一定要和自己的目标知识建设是存在较大关联或重合的,这方面做的还是不错,所以大部分时间都没有跑题跑的太偏了。
硬技能
学历、院校、就职单位 性格江山难改本性难移,只能说尽量保持克制和改善。不忘初心也很重要 为人处世最讨厌乌烟瘴气、帮派和小圈子,除非有必要,小圈子是一个不错的选择,但是小圈子很容易会和前两者有很强的关联性。还是需要一定程度上的假装合群 站队,不站队远比站队还严重。一直以来都不站队,或者抗拒站队,在一个比较强调控制的团队或组织里面,很容易被弄,最后过得也很惨,不过也从侧面反映了,这种团队和组织没必要长待,长久不了;事实却是证明了,不管多少年过去,这种组织或机构要么都死掉了,要么勉强维持着现状。 有时候少一点有意而为,很多时候明知道这样做的结果会如何。但自己偏偏不信邪,并且带着好奇心的故意做一些事情,反过来观察大家的反应,尽管确实很有效果,也相对客观准确的能观察到信息,但实际上不太理想,容易变成掘地自焚。 管理 & 洞察尽管不喜欢也不想做管理岗位,也不愿意去做。主要还是不愿意和人打交道,不想去搞那些麻烦的人和事,也不想承当责任。 但事与愿违,年纪上去了,就该适当的考虑扩宽自身的路子。所以管理岗的一些同事,他们的行为风格是一个较好的学习习惯,和观察机会。透过他们可以间接学习一些成与败的经验。 从小到大洞察能力是不需要做任何评价的,这一个点是先天有优势,但还需要注意一下,不能让自身主观兴趣过多的去主导洞察的目标和信息的获取。先收集信息,后整理和分类。然后适当的对洞察结果做出相应,稳优先,切莫太急躁,因为现在认为干扰信息也挺多的。
软技能
知识深度这里需要明确,这里提到的知识深度不同于公司层面,因为公司层面更多是通过所谓的知识深度来淘汰人的一个借口罢了。 这里更多是结合现阶段自身岗位情况,和未来目标可达岗位情况去指定的知识深度学习计划编解码目标:<了解>编码原理,能够通过码流的一些现象来判断大致的问题 知识范围(粗略,待二次细化):<了解> x264预处理过程 <了解> x264图像分割的过程(预测、宏块划分) <了解> x264熵编码特点(非了解算法内部) <选择了解> x264 码控等相关模块 check point(2-3年完成):产出工具或matlab脚本,演示预处理过程 产出工具,可视化预测、宏块信息(先帧内,后帧间) 知识广度这里需要明确,这里提到的知识深度不同于公司层面,因为公司层面更多是通过所谓的知识广度来淘汰人的一个借口罢了。 这里更多是结合现阶段自身岗位情况,和未来目标可达岗位情况去指定的知识广度学习计划策略器 目标:搞清楚现有的一些策略器,对媒体“流畅”和“质量”的影响有哪些,如何做到的。 知识范围:<了解> 采集 <-> 前处理 策略通路 <了解> 前处理 <-> 编码 策略通路 <了解> 编码 <-> 编码 策略通路 <了解> 编码 <-> 网络 策略通路 <了解> 总控 <-> 各子控 策略通路 check point(1-2年把大致流程搞清楚):
留意几类人
没自知之明,自以为是;关系不便搞僵,不过距离要保持住 自私的人,这些人靠利益维系 小圈子,小帮派。凡是”小“这个东西就很成问题 虚的人 看似很好打交道,其实很难的人
当事情失败的时候,或者出现纰漏的时候,没有任何一个双标狗是无辜的。也没有任何一个双标狗是在工作配合上能够给予别人正向的印象和积极的看法。
做事和人脉圈,能远离双标狗,就尽量远离。如果不能,那尽量投其所好,保持距离就好。
双标行为,其本质是一种认知障碍,对他人,对自身的认知障碍,无法正确的认识客观事物,或选择性认知。同样,双标行为本质还存在一定的心智不成熟或心智上的腐朽,例如不好意思面对自己,怕丢面子等。
但是呢,对于判断双标行为也缺乏强有力的定义和明确,很多时候还是靠我们自身的一个主观印象和私交来判断。实际上,这是一种人和人之间的价值观求交集行为,很多时候容易误判,经验主义和共识主义,也确实就是这么一回事。价值观的形成和被影响原因很复杂,来源于性格、先天环境、后天环境以及自我认知和自我管理。
一般先天环境缺少元素较多的情况,其实自我认知和自我管理成长一般是很容易受限的,比如说,一个家庭环境好的人和一个家庭环境不好的人,他们之间首要的差别就是经济(物质),其次就是见识(精神)。出身家庭困难一些的人,其实从小一直到走进社会的一段时间里,很容易考虑的是养活自己以及眼前的利益(可以看作是格局),出身家庭稍好的一些人,对经济的掌控能力相对会强一些,所以一般不太会有较大的经济安全感,但并不代表就一定能成为有钱人,说白了就是敢花钱。当然这在巨富和巨有势的出身人里,这个理论基本行不通,因为这样的家庭又会产生精神层面建设的失控。
所以呢,需要突破自己的一些固有限制情况,改变自己,这样才更好的去形成一个健全的价值观评价体系,即短暂的窗口期内的多种价值观的包容度。这样或许可以解决对他人评价的识别。
好了说回正题,扯远了。
为何不要把总盯着别人问题的人当回事?
因为这种人要么想着推卸责任,要么就是根本没有意识到自己的问题。处理问题不是正视自己,而是能糊弄过去就糊弄过去,成长和提高速度太慢,和这种人打交道就是浪费生命。 和这样的人纠缠问题太多,就会渐渐陷入事做不好,做不完的窘境。 影响自身情绪,弄不好还会搞了个自我怀疑出来,得不偿失的事情,完全没有太多必要 适当的梳理好自己的情绪,撇清关系,做好自己想做和该做的事情即可。
公司团建有几个地点可以选,除了成都是自由行以外,其他几个都是爬山活动。因为不想爬山,只想看看成都这个城市,拓宽一下自己的见识。
因为是自由行,公司预算完全充足,因此是住在天赋广场的万豪,算是高配水平。
飞机降落,下飞机后,第一个感觉就是熟悉和亲切,因为双流这个机场确实不大,而且很多地方让我第一就能联想到昆明的巫家坝机场,况且行走的路人中大多数都讲着熟悉的西南方言,而且大家的步伐适中,并不像是在赶路。顿时间感到和回家了一样,再加上机场打车到酒店对我们从杭州过去的人来说价格并不是太贵,所以好感度一下子就上来。
一路上和司机聊天的时候,感觉司机不紧不慢,说话语速很缓和,车子开的也不急不躁。沿途看到的基本都是高楼,绿化不是很多,又不少看上去很新的房子,也有不少看上去很陈旧的房子,新鲜感和亲切感瞬间油然而生。带着各种好感和加成的情况下办好了入住。
第二天私下和同事组队去了三星堆,通过网上报名三星堆一日游团提供的信息,我们来到集合点后,成都给我的那种好感在逐渐的发生一些微妙的变化:
土方车开车不文明,闯红灯,还带着油门过弯,差点压到人 城市管理看得出来有很多松懈和似乎投入不足的地方 人口稠密 城市绿化少(相比杭州来说) 路上的车子烧气的有一定比例(这侧面的展现了当地的一些经济情况) 车子以10万和20万附近的为主,尤其是10万左右的居多,基本是过日子的车 BBA出现几率不算高,即便出现也都是40万以内。 车子跨度太大,但45-60万这个区间的车比较少(卡宴、xc90、a8都有,但常见的中间价位车子不算多) 人口素质有待提高,已经是一个人口稠密而且比较大的城市,城市整体发展都还不错,但吐口痰,和非川地区的人不讲普通话等现象很重。 小馆子很多,门面卫生不是很注意。 防疫绿码只认本地的,而且操作略微繁琐。 这次去景区导游给的感觉还可以,比较佛系,素质尚可。 整体能看得出来,整个城市的扩展和发展应该是短期内的,当地很多地方都没有更上变化,这既是机遇也是个问题。说是机遇,主要是因为还有一定的发展余地和空间;说是问题,那是因为有很多不确定因素,同时还存在很多问题。
所以总体来说,成都还是一个比较不错的地方,就目前来说还是很安逸的,但在居住环境上还是有待提高,首先是城市密度太大,老旧房屋太多,马路相较于车流来说较拥挤,所以还是存在很多违和的地方。
不过成都或许作为一个养老的候选地可能是有一定优势。
文件服务器(python)
python有个自带的http版的文件服务器,可以把整个磁盘上的目录都共享出来。
python -m SimpleHTTPServer python -m http.server
windows下调试代码,有符号表和没符号表在某些方面的开发,差别较大,尤其是和一些windows基础库或偏底层的相关性较大的部分。巨硬的符号表服务器访问比较慢,一般为了能够快速进入调试模式,都是提前下好符号表,下面是根据遍历本机所有exe、dll进行符号表匹配并下载的命令
symchk /r C:\Windows\System32\ /s srv*D:\sym*http://msdl.microsoft.com/download/symbols这样做只能加快本机调试的速度,对于其他环境上的dmp解析,远程调试可能用处不大,主要取决于系统中各类库的版本是否和本机的一致。
作为一个写c++98写习惯的人,对于c++11开始新引入的一些修饰关键字已经有些模糊,尤其是override已出现,整个人就有点困惑,并且在平日写代码里面还是沿袭了c++98虚函数重载的写法,被同组的小鲜肉鄙视(其实他种种高傲又和自身水平不相称的行为,我是相当鄙视的!),问其原因又未告知。果断看c++11书先了解。
首先看看下面两种写法:
//写法一:
class A {
public:
virtual void A() = 0;
};
class B : public A {
public:
virtual void A() {}
};//写法二:
class A {
public:
virtual void A() = 0;
};
class B : public A {
public:
void A() override {}
};本质上上面两种写法并无太大差别,由于A这个类是纯虚类,子类只要存在有函数没有进行重载,编译阶段结汇出现报错,此时override在这里可有可无,区别不大。
但如果是下面两种写法,override就体现了作用
//写法一:
class A {
public:
virtual void A() = 0;
void A(const int a) {}
virtual B() {}
};
class B : public A {
public:
virtual void A() {}
virtual B();
};//写法二:
class A {
public:
virtual void A() = 0;
void A(const int a) {}
virtual B() {}
};
class B : public A {
public:
void A() override {}
void A(const int a) override {}
void B() override;
};由于带参数的A函数是非虚函数,仅仅可以通过“覆盖”的方式进行,而使用override进行修饰,将会报错属性错误。这样可以用来检查类继承时候,成员函数属性错误的情况 由于加了override,在编译阶段,写法二会检查B函数在子类中是否已经被实现,如果没有实现会报错。而对于写法一来说,只有子类的B函数被使用到的时候,才会在链接期进行检查。这样可以提早发现代码漏实现的情况。
奇偶数判断优化
一般情况下判断奇偶数都是用
if (0 == a % 2)但可以优化为:
if (0 == a & 1)取偶与取奇
有时候需要对一些数进行取偶,那么代码可以优化为:
取偶:a += a&1
取奇:a += 1-(a&1)
公司代码用了syslog,但由于一般公版的docker基础镜像里并没有syslog服务器。因此需要做个单独安装。
启动镜像后执行如下命令,即可完成syslog服务的安装和启动。
apt update && apt install rsyslog -y
rsyslogd通过一下命令测试一下
logger "test"在/var/log/syslog中出现了刚才的日志就说明服务安装成功。
最近在测试一个T4 gpu执行性能的问题,通过nvidia-smi来对显卡的运行效率和状态进行收集和统计。
在使用的过程中发现,该工具不同参数下对性能的影响不同。负载情况如下图。
任务为20个720p 15fps的视频转码+推理任务。相当于每秒钟执行4500次解码+4500次编码+4500次推理。
在执行nvidia-smi dmon时,发现性能影响很小;执行nvidia-smi pmon时,性能影响相对明显。
由于没有找到比较详细的信息和解释,初步推测和性能采样有关。pmon模式下,需要对每个进程做采样,会降低一些执行性能。
在用户角度来看,linux有两种信号量,system v和posix两种。
之前由于需要快速开发出东西来,就随便选了一个信号量来使用,后来才发现是system v,在使用过程中也遇到了一些坑。
sem_key_ = ftok(“file_exist”, 'a');
int flag = 0666;
flag |= IPC_CREAT;
sem_id_ = semget(sem_key_, 1, flag);
if (-1 == sem_id_) {
std::cout << "semaphore create failed" << std::endl;
return;
}
union semun sem_union;
sem_union.val = 1;
if (semctl(sem_id_, 0, SETVAL, sem_union) == -1) {
std::cout << "semaphore semctl failed" << std::endl;
return;
}这里需要注意的是,ftok的第一个传入函数必须要某个存在的文件,因为需要通过具体的文件,去访问对应的nodeid,并做hash值。如果文件不存在,那么返回值将会是-1。
在安装linux的时候,如果选择了lvm文件系统,当某个特定分区文件不够用的时候,直接通过resize即可实现在线动态扩容分区。
但由于当时为了减少一些开销,并没有使用lvm作为中间管理器,直接使用物理磁盘的分区。
debian是运行在vmware中,对于磁盘扩容比较简单,只需要进行配置一下,磁盘大小即可进行快速伸缩。
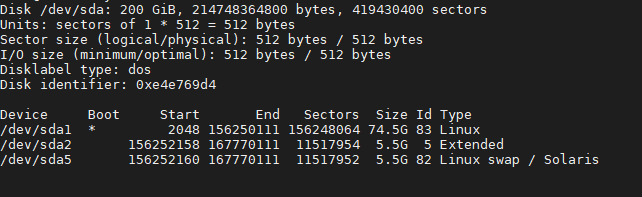
设置好vmware磁盘后,进入linux后执行fdisk -l检查硬盘大小,已经生效。
可以看到磁盘总大小200g,sda1+sda2还保持在75g。这时候执行apt install gparted后运行分区工具。
这时候先禁用swap分区,并删除swap对应的逻辑分区,接着执行修改sda1分区大小。
设置成需要的分区大小之后,在对剩余的空间执行创建对应的swap分区。然后执行mkswap /dev/sda5,查看swap分区的uuid。
执行nano /etc/fstab,修改对应的swap分区uuid,重启后即可。
公司大佬用cudnn写了一个推理库,用于做背景分割。新到一台用于做测试的服务器,但sre和it都不管我,而我又是集成这个cudnn的人。所以只能自己亲自上,淡然还有大佬的帮助下成功安装了系统和驱动。
准备工作,一个新安装的ubuntu server 18。
下载好驱动、cuda、cudnn、tensorrt:
NVIDIA-Linux-x86_64-418.165.02.run
cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
cuda-ubuntu1804.pin
libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb
libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.deb
nv-tensorrt-repo-ubuntu1804-cuda10.1-trt6.0.1.5-ga-20190913_1-1_amd64.deb其中需要注意的是,除了显卡驱动,其他部分都要下deb包,否则会出现打不上的情况。
然后按照教程的路线,执行dkpg -i和api install就好