【docker】容器中启动syslog
公司代码用了syslog,但由于一般公版的docker基础镜像里并没有syslog服务器。因此需要做个单独安装。
启动镜像后执行如下命令,即可完成syslog服务的安装和启动。
apt update && apt install rsyslog -y
rsyslogd通过一下命令测试一下
logger "test"在/var/log/syslog中出现了刚才的日志就说明服务安装成功。
公司代码用了syslog,但由于一般公版的docker基础镜像里并没有syslog服务器。因此需要做个单独安装。
启动镜像后执行如下命令,即可完成syslog服务的安装和启动。
apt update && apt install rsyslog -y
rsyslogd通过一下命令测试一下
logger "test"在/var/log/syslog中出现了刚才的日志就说明服务安装成功。
最近在测试一个T4 gpu执行性能的问题,通过nvidia-smi来对显卡的运行效率和状态进行收集和统计。
在使用的过程中发现,该工具不同参数下对性能的影响不同。负载情况如下图。

任务为20个720p 15fps的视频转码+推理任务。相当于每秒钟执行4500次解码+4500次编码+4500次推理。
在执行nvidia-smi dmon时,发现性能影响很小;执行nvidia-smi pmon时,性能影响相对明显。
由于没有找到比较详细的信息和解释,初步推测和性能采样有关。pmon模式下,需要对每个进程做采样,会降低一些执行性能。
在用户角度来看,linux有两种信号量,system v和posix两种。
之前由于需要快速开发出东西来,就随便选了一个信号量来使用,后来才发现是system v,在使用过程中也遇到了一些坑。
sem_key_ = ftok(“file_exist”, 'a');
int flag = 0666;
flag |= IPC_CREAT;
sem_id_ = semget(sem_key_, 1, flag);
if (-1 == sem_id_) {
std::cout << "semaphore create failed" << std::endl;
return;
}
union semun sem_union;
sem_union.val = 1;
if (semctl(sem_id_, 0, SETVAL, sem_union) == -1) {
std::cout << "semaphore semctl failed" << std::endl;
return;
}这里需要注意的是,ftok的第一个传入函数必须要某个存在的文件,因为需要通过具体的文件,去访问对应的nodeid,并做hash值。如果文件不存在,那么返回值将会是-1。
在安装linux的时候,如果选择了lvm文件系统,当某个特定分区文件不够用的时候,直接通过resize即可实现在线动态扩容分区。
但由于当时为了减少一些开销,并没有使用lvm作为中间管理器,直接使用物理磁盘的分区。
debian是运行在vmware中,对于磁盘扩容比较简单,只需要进行配置一下,磁盘大小即可进行快速伸缩。
设置好vmware磁盘后,进入linux后执行fdisk -l检查硬盘大小,已经生效。
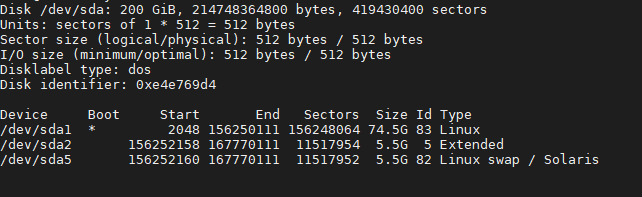
可以看到磁盘总大小200g,sda1+sda2还保持在75g。这时候执行apt install gparted后运行分区工具。
这时候先禁用swap分区,并删除swap对应的逻辑分区,接着执行修改sda1分区大小。
设置成需要的分区大小之后,在对剩余的空间执行创建对应的swap分区。然后执行mkswap /dev/sda5,查看swap分区的uuid。

执行nano /etc/fstab,修改对应的swap分区uuid,重启后即可。
公司大佬用cudnn写了一个推理库,用于做背景分割。新到一台用于做测试的服务器,但sre和it都不管我,而我又是集成这个cudnn的人。所以只能自己亲自上,淡然还有大佬的帮助下成功安装了系统和驱动。
准备工作,一个新安装的ubuntu server 18。
下载好驱动、cuda、cudnn、tensorrt:
NVIDIA-Linux-x86_64-418.165.02.run
cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
cuda-ubuntu1804.pin
libcudnn7_7.6.5.32-1+cuda10.1_amd64.deb
libcudnn7-dev_7.6.5.32-1+cuda10.1_amd64.deb
nv-tensorrt-repo-ubuntu1804-cuda10.1-trt6.0.1.5-ga-20190913_1-1_amd64.deb其中需要注意的是,除了显卡驱动,其他部分都要下deb包,否则会出现打不上的情况。
然后按照教程的路线,执行dkpg -i和api install就好
用信号量来做共享内存的互斥操作,执行semop阻塞式调用。
结果发现执行p操作(加锁)会较低概率不定期的出现EINTR失败,查看linux手册,看到如下片段:

也就是当线程正在对信号量进行操作时,刚好出现该线程捕捉到了一个信号,这时候刚好接收到某个信号执行了相应信号的相应中断处理函数。
这主要是由于信号是以进程为单位,而具体某个信号会被进程内部的哪一个线程执行,这是极有可能不可预知的(主要有操作系统而定)。因此在这种情况下时,如果semop执行出现了一个EINTR错误,那么只需要再次重启调用semop就好。
解决这个问题的办法有两个:
1,通过屏蔽掉大部分该线程不关心的信号来解决,但是这样有可能会出现误屏蔽的操作情况。
2,单独开启一个线程来执行sigwait,作为信号处理线程。
最近在查coredump的时候,一直发现堆栈不完整。于是很好奇abort的信号默认情况下会如何处理。
网上查了一下,发现信号分为进程间信号和多线程间信号。
进程间信号,即进程之间可以互发信号,也可以进程内部某个线程来产生信号。由系统库提供支持。
多线程间信号,即线程之间互发信号,且指定具体线程来接收并处理。由pthread库提供支持。
由于coredump的抓取过程,应该没有做过特殊处理,因此使用的就是进程间信号。那么进程内,当某个线程执行某个代码时,产生了abort信号,信号会由谁来负责处理?实际测试的结果是由具体产生abort信号的线程来处理执行。
查了一下网上的解释,信号的处理,是由内核态准备切换回用户态时来处理,由于在态切换时,主动地插入了一个函数跳转指令,进而转为执行信号处理函数。因此由产生abort信号的线程来处理实现即简单,也符合逻辑。
由于是中断处理,这一点上可以看做和windows类似。
在写代码的时候,有一些技巧和方法已经快成为成为了众矢之的,主要还在于代码的可阅读性,以及易错性上。
被列为经典的几种方法或技巧中有一些还是能用尽量少用:goto、递归、状态机。
写过汇编的人都知道,汇编改变指令执行地址的方法里,除了call/ret,还有大量的jmp/sjmp来构成一个程序,如果仅仅使用call/ret来写,有时候代码会变得非常臃肿,而且让本来就难以理解的汇编变成更难阅读的代码,所以就会用jmp/sjmp来改变指令执行的地址。当然这只是抛砖引玉,在汇编里改变指令执行地址可不仅仅这两对指令,还有很多其他指令和方法。
而goto是我在学c语言的时候接触到的,c++也依然部分支持(具体看编译器和相应语言标准)。goto更像是汇编中变成思维的一种移植,类*inx系统的内核代码里也拥有大量的goto使用。
在面向过程变成里,使用goto似乎并没有太大不适,而且也能在一定程度上减少代码规模。但goto若用的不好,带来的效果适得其反。而且容易使得代码逻辑变得极其复杂,非常的绕思维。
goto在短小精干的代码里,可以较少的带来阅读和易错现象,而且要把goto用的好,用的巧妙,还非常考验写代码的人如何编排代码流程和排版。
若没有过硬的逻辑思维能力和计算机式的思维能力,goto能避免最好避免,尤其是在写一些对代码体积和性能要求不是太高的情况下。
代码的性能和体积其实可以通过其它方式优化,未必非要这样。
在数据结构和一些基本算法的教学里,递归是用的最频繁的。因为一些解题思路用递归来执行比较接近人类的思维方式,更容易理解。
栈帧的维护和执行,也是通过递归的方式进行的;可见递归的重要性。但是递归还存在容易让栈空间溢出,以及无限递归的出现,同样也存在一些不便于理解代码的情况。因为每一次递归函数的重入,都会使用新的栈帧对象,导致局部变量不是同一个的现象,这恰恰很有可能会让人在无意间错会递归的过程。
若不是解决问题的模型比较接近递归或代码短小精干的情况下,能用别的方式化解递归,最好通过其它方式。
状态机是一个基本的原型机或记录器,要从时间的角度出发讨论,状态机应该最先出现在高频模拟电路里,一些信号同步机制与触发应该是最接近状态机思维。
只不过后面称做状态机的都是从数字电路开始,状态机在设计门电路时,是最好用的一种分析工具或辅助工具。但在协议栈、驱动、直接和硬件交互的代码里,往往有着很多的状态机。
状态机由于仅仅是表征一种状态跃迁并联系成一个系统的工具,并未对状态跃迁的规则做约束,因此状态机很有可能会被设计的非常复杂,详情可以参考协议栈代码。若是过于强调状态机的特性,在写一些复杂度较高的策略模型时,往往是容易简单问题复杂化,甚至力不从心。
建议将状态机解耦,改为状态化就好。接触每种一状态之间的耦合度,会让代码较为简单些,如非常强调性能,可以通过其它方式解决。
最近在ios上出现将多个sdk放到一个app时,有各种开源静态库冲突的问题;于是考虑将自己用到的库进行打包成动态库版本,以此解决冲突问题。
在进行打包成动态库时,发现x264问题最大。打包出来的库在链接期出现text relocations错误,网上找了以后发现基本都是进行忽略这个错误,事实上这个错误忽略了没用,app启动时还是会出现相应的crash。
换了几个版本的xcode进行测试,发现x264编译会出现不同情况的告警和错误,根据底部罗列的参考文章,估计xcode的编译器可能也有一些bug。
后来模仿android上的编译方式,在x264里加入了–enable-pic和–disable-asm顺利编译通过,但由于osx和xcode版本的因素,模拟器上的并没有编译出来,仅仅编译了armv7和arm64。
参考文章:
MacOSX下编译linphone(text-relocation错误说明)
libxxx.so- text relocations问题的终极解决方案(android)
由于最近在接手一些脏活累活,所以就被拉来解决一下ios下关于播放设备切换的问题,实际上当听到这个问题的现象是基本可以判断播放设备切换的时候没有重设播放参数引起的。
后面说为了给我个环境去调一下,iMac拿过来很开心的执行编译,谁知道编译隐形失败。。。之所以说隐形失败是gyt_webrtc和ninjia没有报错什么让人感觉在意的错。
捣腾了几天,七弄八弄的最后查到由于在执行gyp_webrtc后通过gyp生成的ninja中有几个主要工程配置没有生成。
当时由于感觉找到完整的问题了,今天过来就直接干脆手动执行后续的步骤把整个编译执行完成。起初发现有问题,因为i386的构架被打包到静态库了,然后网上找到删除掉i386方法,随之删掉i386手工合成最终的包,加入到xcode工程里面跑,结果连接失败,出现符号找不到。
继续查问题,最终还是留意到了gyp_webrtc的错误,错误如下:
iMac:build hyt$ ./ios.sh release
Updating projects from gyp files...
Traceback (most recent call last):
File "../src/webrtc/build/gyp_webrtc", line 115, in &lt;module&gt;
gyp_rc = gyp.main(args)
File "/Users/hyt/webrtc/src/chromium/src/tools/gyp/pylib/gyp/__init__.py", line 538, in main
return gyp_main(args)
File "/Users/hyt/webrtc/src/chromium/src/tools/gyp/pylib/gyp/__init__.py", line 523, in gyp_main
generator.GenerateOutput(flat_list, targets, data, params)
File "/Users/hyt/webrtc/src/chromium/src/tools/gyp/pylib/gyp/generator/ninja.py", line 2469, in GenerateOutput
pool.map(CallGenerateOutputForConfig, arglists)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/multiprocessing/pool.py", line 251, in map
return self.map_async(func, iterable, chunksize).get()
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/multiprocessing/pool.py", line 567, in get
raise self._value
AssertionError: Multiple codesigning fingerprints for identity: iPhone Developer
网上查到主要是证书冲突问题。
解决步骤大致如下:
1,列出有效证书
security find-identity
2,寻找证书配置gyp文件
find . -name common.gypi | xargs grep CODE_SIGN_IDENTITY
会看到这么几行:
./chromium/src/build/common.gypi: ‘CODE_SIGN_IDENTITY[sdk=iphoneos*]’: ‘iPhone Developer’,
./chromium/src/build/common.gypi: ‘CODE_SIGN_IDENTITY[sdk=iphoneos*]’: ”,
3,用之前证书列表中Valid identities only的字段替换‘iPhone Developer’里面的内容
4,重新执行gyp_webrtc即可
由于最近在看开源代码,手里的开源代码为了能够比较好的可移植性,在代码中加了很多宏,并在linux用了pthread库。
其中对于pthread的条件变量理解很是疑惑,看pthread手册后还是有不解,感觉条件变量用起来太奇怪,在pthread_cond_wait时,互斥到底有没有释放等问题上没搞明白,上代码调试后遍便豁然开朗。先贴一个修改过的官方代码例子:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 3
#define TCOUNT 10
#define COUNT_LIMIT 12
int count = 0;
pthread_mutex_t count_mutex;
pthread_cond_t count_threshold_cv;
void *inc_count(void *t)
{
int i;
long my_id = (long)t;
for (i=0; i < TCOUNT; i++) {
pthread_mutex_lock(&count_mutex);
count++;
/*
Check the value of count and signal waiting thread when condition is
reached. Note that this occurs while mutex is locked.
*/
/*if (count == COUNT_LIMIT)*/ {
printf("inc_count(): thread %ld, count = %d Threshold reached. ",
my_id, count);
pthread_cond_signal(&count_threshold_cv);
printf("Just sent signal.\n");
}
printf("inc_count(): thread %ld, count = %d, unlocking mutex\n",
my_id, count);
pthread_mutex_unlock(&count_mutex);
/* Do some work so threads can alternate on mutex lock */
sleep(1);
}
pthread_exit(NULL);
}
void *watch_count(void *t)
{
long my_id = (long)t;
printf("Starting watch_count(): thread %ld\n", my_id);
/*
Lock mutex and wait for signal. Note that the pthread_cond_wait routine
will automatically and atomically unlock mutex while it waits.
Also, note that if COUNT_LIMIT is reached before this routine is run by
the waiting thread, the loop will be skipped to prevent pthread_cond_wait
from never returning.
*/
pthread_mutex_lock(&count_mutex);
while (1) {
printf("watch_count(): thread %ld Count= %d. Going into wait...\n", my_id,count);
pthread_cond_wait(&count_threshold_cv, &count_mutex);
printf("watch_count(): thread %ld Condition signal received. Count= %d\n", my_id,count);
printf("watch_count(): thread %ld Updating the value of count...\n", my_id,count);
//count += 125;
printf("watch_count(): thread %ld count now = %d.\n", my_id, count);
}
printf("watch_count(): thread %ld Unlocking mutex.\n", my_id);
pthread_mutex_unlock(&count_mutex);
pthread_exit(NULL);
}
void cond_test()
{
cout << "---------- cond_test ----------" << endl;
int i, rc;
long t1=1, t2=2, t3=3;
pthread_t threads[3];
pthread_attr_t attr;
/* Initialize mutex and condition variable objects */
pthread_mutex_init(&count_mutex, NULL);
pthread_cond_init (&count_threshold_cv, NULL);
/* For portability, explicitly create threads in a joinable state */
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
pthread_create(&threads[0], &attr, watch_count, (void *)t1);
usleep(1000*20);
pthread_create(&threads[1], &attr, inc_count, (void *)t2);
//pthread_create(&threads[2], &attr, inc_count, (void *)t3);
/* Wait for all threads to complete */
for (i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
printf ("Main(): Waited and joined with %d threads. Final value of count = %d. Done.\n",
NUM_THREADS, count);
/* Clean up and exit */
pthread_attr_destroy(&attr);
pthread_mutex_destroy(&count_mutex);
pthread_cond_destroy(&count_threshold_cv);
//pthread_exit (NULL);
}
首先说一下例子,主线程创建一个inc线程和watch线程,每次inc线程激活条件变量,这时watch线程被激活。
为了测试在pthread_cond_wait函数进入是,互斥有没有被释放掉。因此注释掉高亮部分的代码,发现inc线程永远不会被激活。说明在pthread_cond_wait时会将互斥进行释放,接下来等有空一定要抽空看看pthread的实现代码。以及比较一下vs是如何将pthread库进行伪封装后在windows上提供使用的。
首先,我是一个完全的linux开发初学者,我仅仅在windows做开发,由于兴趣与工作的缘故碰到了通过已有的socket模型搭建好的网络库。下面就说说在windows下,我了解到socket模型(准确是标准socket模型,对于微软封装过的一些模型我不是很清楚)
1,普通阻塞是socket:
普通的socket模型,就是msdn中对socket api族介绍中最简单的那个例子。这种最简单,在执行效率上相对较低,在处理send/recv(sendto/recvfrom)时,函数是处于阻塞的。在简单环境,或者写一些简单的测试工具时,这是一种比较理想的用法。
2,同步 select模型
同步select模型,其实可以是理解为普通阻塞式sokcet的一个扩展,就是利用select来对socket句柄进行监听,避免由于调用send/recv(sendto/recvfrom)时出现阻塞。
3,异步select模型
异步select模型,可以看成是同步select的一种变化。即send/recv(sendto/recvfrom)函数不会阻塞,调用立即返回,并需要同时配合select函数一同使用。
4,IOCP
异步IO模型,使用上可以和异步select模型类比;但这并非标准socket模型。
然后接下来再说一下几个模型的差别:
1,普通socket、select模型,在调用send/recv(sendto/recvfrom)函数时,均会出现一次多余的内存拷贝。即,用户态传如一个buffer时,在转为交给协议栈之前,必须通过内存拷贝的方式,将数据复制到内核态的内存中。
2,windows上select集合最大值大约是64/128(有系统版本决定);换句话说一个调用select函数的线程,最大可监听64/128个socket句柄
*3,据网上各种文档介绍到,select是基于内核态线程轮询完成,具体不详,有待考证!
4,IOCP 和其他几者最大区别在于内存拷贝上,由于IOCP是通过共享内存(即内存映射)。在windows中内存映射属于一个特殊的内存管理器的管辖范围,他即不属于内核态,也不属于用户态内存,当对于内核态或用户态线程来说,只要通过调用内存映射函数,就可以直接访问这块内存(但得到的逻辑地址或许是不同的)。
由于在WSARecv/WSASend之类函数中,提交的均为共享内存,因此无需做任何内存拷贝。所以在IOCP上,性能要更好的多。同时本人的了解范畴也仅限于这一块,对于IOCP的事件投递过程并不是很清楚,但根据《软件调试》一书中对“windows系统调试/windows软件调试”设计的讲述来看,IOCP这种的实现应该是在内核态也同样创建了和用户态以之对应的内核服务线程。
接着再说说linux,刚刚看了一下epoll的介绍。
发现epoll是基于事件回调+内存映射来实现IO上的高效;同时这篇文章也还介绍了几个常用的socket模型在linux中的大概实现。通过这篇文章至少能够看出,linux和windows在对socket的实现上存在很大的相似。
可见linux和windows存在很多相似的地方,如果linux和windows互相对应着学,理解起来可能会快很多。
在windows上调试真机,只需要装驱动就行了。
linux上简单一些,直接插上去就可以认出usb设备,但麻烦的是需要配置相应的usb配置项,步骤如下:
1,执行一下lsusb,得到下面的东西
Bus 002 Device 002: ID 2299:1411 Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
2,因为手里面的是个山寨机,所以显示不出描述来也是正常的。下面这条就是
Bus 002 Device 002: ID 2299:1411
修改/etc/udev/rules.d/51-android.rules的配置文件(如果没有这个配置文件,就直接创建好了)
SUBSYSTEM=="usb", ATTR{idVendor}=="2299", MODE="0666", GROUP="plugdev"
然后重启一下udev服务
/etc/init.d/udev restart
接着在重启adb
adb kill-server adb start-server
装了debian 8以后,在用最新版的eclipse(mars)+adt调试android代码时,发现logcat日志是有的,但是无法显示在界面上。
查了一下网上的情况,好像很多人都有过。问题都好像出现在gtk相关的界面问题上。
有两种修改方法
— 第一种 —
相应的配置修改配置文件 /workspace/.metadata/.plugins/org.eclipse.core.runtime/.settings/com.android.ide.eclipse.ddms.prefs
为如下内容:
ddms.logcat.auotmonitor.level=error ddms.logcat.automonitor=false ddms.logcat.automonitor.userprompt=true eclipse.preferences.version=1 logcat.view.colsize.Application=200 logcat.view.colsize.Level=70 logcat.view.colsize.PID=50 logcat.view.colsize.TID=50 logcat.view.colsize.Tag=170 logcat.view.colsize.Text=300 logcat.view.colsize.Time=140
— 第二种 —
或者在执行eclipse之前,设置环境变量
export SWT_GTK3=0 eclipse
我采用了第二种方式,就可以正常显示了