一些代码优化中的小技巧(表达式优化部分)
奇偶数判断优化
一般情况下判断奇偶数都是用
if (0 == a % 2)但可以优化为:
if (0 == a & 1)取偶与取奇
有时候需要对一些数进行取偶,那么代码可以优化为:
取偶:a += a&1
取奇:a += 1-(a&1)一般情况下判断奇偶数都是用
if (0 == a % 2)但可以优化为:
if (0 == a & 1)有时候需要对一些数进行取偶,那么代码可以优化为:
取偶:a += a&1
取奇:a += 1-(a&1)
bool srs_is_little_endian()
{
// convert to network(big-endian) order, if not equals,
// the system is little-endian, so need to convert the int64
static int little_endian_check = -1;
if(little_endian_check == -1) {
union {
int32_t i;
int8_t c;
} little_check_union;
little_check_union.i = 0x01;
little_endian_check = little_check_union.c;
}
return (little_endian_check == 1);
}
通过上面代码片段可发现little_check_union的大小只有4个直接,通过访问最后一个字节来判断当前平台(软件+硬件平台)大小端情况。
同时也可以利用union来进行访问,这样的访问方式较直接安位操作来说简单性能差一些,但也只一种较为简便和安全的做法。(虽然不是绝对安全的做法)
再说baseline做强交互不利因素之前,先说说现在直播的场景情况。

场景如上图,推流段不是移动平台,就是PC机。当然最近几年也出现专门用来推流的定制盒子,本质不是一个嵌入式windows,就是一个android设备(android设备较多)。
然而上述提到的这些问题,就造就了可能大家会想到flash、h5和native应用,对于native应用来说还好,开发起来虽然周期长,但可塑性比较强。对于flash和h5来说可选择余地就非常小了。
暂时不说flash和h5本身在做双向强交互直播是否可行,先说一说两者采用的协议类型。对于flash来说:
接下来说一说h5方式的直播:
通过以上可以得知,实际上在使用x264编码时,最终在profile的选择上基本就限制在了baseline、main、high三种。从算法复杂度上来上讲,baseline是最为简单,而high是较为最为复杂(主要是预测模型比前两者多不少)。
不过在实际工程应用中,我们还是做了一个比较脑残又没有办法的决定,那就是使用baseline。原因有二:
考虑到使用场景和当时网络的大环境,确实选择openh264,即是无奈的选择,也是一个极其脑残的选择。说无奈主要是现实,说脑残是因为压根就没有做过定性分析。。。。。。
然后接下来就开始“数落数落”baseline不适合做双向强交互直播的原因。在看x264的代码时,偶然对编码中的预测做了少许的了解。
—- 我是装逼的分割线 1号 —-
传统上对一副图像的处理,一般的理论是基于“分割”,由于图像一般情况下具有前景和后景之分,也就是说,前景和背景之间存在着大量的局部图像细节,对于图像压缩中的思路往往是,尽量将相似的区域用差别不大的统一一个区域去表达,对于差异较大的区域,尽量在用较多的数据量去存储以此保留图像的局部细节。
那么就会存在如何分割图像的问题。如果是一副简单单值图,例如大学时代我做的非矢量图压缩(理论基础差不多),那么只需要根据图像分辨率,做相应的最佳分割快大小计算,并做简单切割即可。将区域内的有色的点和无色的点进行记录,并按做纵向或横向切割成色带,记录色带中有色点或者无色点的坐标值即可。整个思路转换成代码思维,类似于多级联映射表。当然这个做法的关键还在于公式如何设计,即如何动态计算切割区域的大小。由于是做印章方面,所以图像不会太大,因此公式也非常简单。
最终压缩可以理解成单值图的无损压缩,实测试之后,和转换成矢量图之后的文件大小相比,应该两者都会比现在主流的大部分图像编码小非常多。
接着通过类似7z、rar工具里面的二进制压缩算法进行再次压缩,文件最大还能缩小60%左右。一个500k的位图最终生成文件在3k左右。
—- 我是装逼的分割线 2号 —-
由于有上面的实践基础,因此在理解264的压缩时,我也能够理解到“分割”时的重要性。
首先,在baseline模式下,x264的预测模型相对于其他high来说,非常简单。这样的情况就决定了,在局部的细节切块相比high来说有着很多不足,对二进制数据进行压缩前就已经输在起跑线了。即细节丢失比high多。
其次在编码算法上(或者说压缩算法上),baseline仅仅使用cavlc,而对其他两者来说他们既可以使用cavlc也可以使用cabac。没有做过定性或者定考量分析,但通过网上资料获知,cavlc的效率似乎没有cabac高,具体在哪些指标有所体现目前暂时并不清楚。
因此,可以得知。baseline除了在实时性上满足了双向强交互直播对时间的要求,对于相同质量下的压缩比并不是很好。但又由于baseline相对其他profile的简单特点,其实广泛性还是比较不错的。
手里有台android 2.3时代的三星手机,对baseline的视频进行解码,手机基本可以应付(不清楚是硬解还是软解,因为当时的arm好像还有没有对264硬解做太多优化),但相同视频长度的main和high的话,那就有点头疼了。看来baseline对老旧手机还是比较“良好”的。
在x264中,由于单一宏块预测方向与264规范定义实际上是一直的,即预测方向只有:左(left)、上(top)、左上(left-top)、右上(right-top)。
没有其他的另外四个方向,估计可能是zig-zag的数据排列有关,或只是由于对称关系,不需要做重复预测。
有上述4中预测方向,x264中定义了几种邻居关系(下面拿I帧4×4的宏块距离说明):
最近一直在通过远程桌面的方式使用笔记本,突然发现matlab死活都打不开,出现如下错误
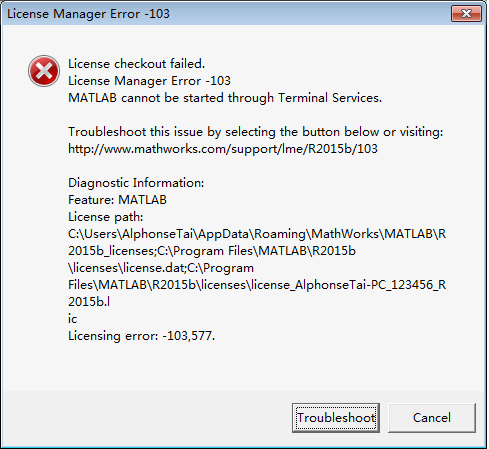
起初以为安装出问题,后来网上看了下才知道是远程桌面的锅。直接用基本登录,问题解决。
在数据结构和数学中,都有着有向图的理论路径计算和迭代。一下是线性代数中对有向图的一个抽象。


可见, 如果需要枚举出某个断点到另一个断点的可能路径的话,那就是对A矩阵进行做幂计算。例如计算1号端点到4号断点4次中转以内的可能路径,那么只需要对A矩阵做四次幂运算(1,2,3,4),然后求和4种幂运算中的a14,即可得到可能的路径数。
当用c/c++做浮点数转换成整数时,处理一般都很简单,丢掉小数位置保留整数部分(没有看过具体的汇编,不清楚如果浮点数表达的位置太大,以至于整数溢出的情况)。
而在matlab中,浮点数转换成整数时候,会有四舍五入的规则,即:
uint8(0.499) = 0
uint8(0.5) = 1
所以在用matlab时,需要注意到数值转换与c/c++的不同。
首次安装完matlab时,在导入授权后,打开发现一堆警告,各种命令不可用,大致内容如下:
Warning: C:\Program Files\MATLAB\R2012a\toolbox\local\pathdef.m not found.
Toolbox Path Cache is not being used. Type ‘help toolbox_path_cache’ for more info
Undefined function or variable ‘ispc’.
Warning: MATLAB did not appear to successfully set the search path. To recover for this session of MATLAB, type “restoredefaultpath;matlabrc”. To find out how to avoid this warning the next time you start MATLAB, type “docsearch problem path” after recovering for this session.
Warning: Duplicate directory name: C:\Program Files\MATLAB\R2012a\toolbox\local.
Warning: Initializing Handle Graphics failed in matlabrc.
This indicates a potentially serious problem in your MATLAB setup,
which should be resolved as soon as possible. Error detected was:
MATLAB:undefinedVarOrClass
Undefined variable “graphics” or class “graphics.internal.initializeMATLABRoot”.
Warning: Initializing Java preferences failed in matlabrc.
This indicates a potentially serious problem in your MATLAB setup,
which should be resolved as soon as possible. Error detected was:
MATLAB:UndefinedFunction
Undefined function ‘usejava’ for input arguments of type ‘char’.
> In matlabrc at 113
Warning: Failed to add default profiler filters.
> In matlabrc at 168
>> rtwintgt -setup
Undefined function ‘rtwintgt’ for input arguments of type ‘char’.>> help toolbox_path_cache
Undefined function ‘help’ for input arguments of type ‘char’.
实际上是安装的时候路径出错,用管理员模式启动,然后执行这个命令:
restoredefaultpath;matlabrc
matlab执行环境变量恢复以后,系统正常可用。
好像从vs2010开始,vs自带的max宏就不再被推荐为C++中使用的首选,而是尽可能的改为std::max这个模板函数。
在effective c++中也讲到了max宏和std::max之间的差别(但有时使用起来,还是不如max宏来的方便,尤其是当max的入参不是同一个类型时。)
好了,说正事。
在vs2010中,std::max被定义为一个模板函数,其中函数的参数类型推导主要依赖于第一个参数;且std::max被inline修饰。在vs中,inline的强度并没有forceinline那么强,因此编译时,编译器即可能会让模板函数展开,也有可能不会让模板函数展开。
有时候有些开源项目中,大量的使用了std::max,这也会进一步的导致编译速度减慢,编译出来的文件变大;这里面除了inline还有一定的原因和模板的特性有关。
为了解决这类问题,有事不得不做出一些折中或妥协。即,当杜写一个公共函数,在该函数中将std::max进行特例化,以此来达到优化编译的目的。假设在不调整诸如fpo之类的优化参数时,编译器都会一定只会将std::max进行仅有的有限次实例化,且也可以控制函数是否进行inline。编译时不仅加快了编译速度,同时也减小了编译输出文件的大小。
所以在一些实际项目中,如果对编译产出的要求比较高,有时不得不牺牲代码设计和可阅读性来达到目的。
本来标题想取名成 《如何做好代码的性能优化》,但发现如果仅仅说代码性能优化的话就太狭义了。
最近一年一直在单线程框架的工程上写代码,阅读框架代码以后,不禁感叹道:“这个框架的设计者不仅是个高手,而且对windows相当了解,甚至借鉴了windows内核里面的一些设计元素。”
首先介绍一下我手里的这个框架:
1,总体来说,整个程序几乎就是单线程+异步(对于DNS解析、IO操作等一些耗时或难以异步的模块,会另启一个线程去执行和管理)。
2,在这个单线程框架中,所有的业务、网络协议栈、数据处理都在挂在这个单线程中去运行,并且绝大对数情况和业务下面都能够很好的运行。
3,模块间通讯采取模拟异步/同步事件、异步/同步消息的方式来完成
4,数据通讯很简单,直接用堆内存传递,用完立即释放。
5,定时器是最简单的“轮询”方式实现(并非真正轮询)
现在遇到一个比较严重的问题,就是在这个单线程模型中,由于开发的时候存在编码人技能层次不齐,以及任务力度控制不均匀。
导致开发一些功能在获得执行时间时,执行时间太长或没有及时的将任务中断并将执行时间让给其他任务执行。
这样的现象导致最严重的问题,自身流程过长,效率不一定高(如果还依赖其他模块的执行结果)。并且其他模块不能及时的拿到执行时间,并将执行结果及时反馈。进而引起血崩效应,导致部分要求时效性高的功能出现问题。
为了解决这类问题,就要做程序性能上的优化。这个问题上,一般采取的优化策略有几种:
1,代码级优化,就是通过各种技巧,将本来执行效率低的代码进行一点一点的修改并加快。这种优化方式周期长,效果不见得很明显,但对于长久来说是具备一定好处的;可以让优化者能够熟悉和了解整个代码的运行情况和流程等。
2,业务/功能优化,通过将长流程或者耗时的流程将功能和业务优化掉。然长流程变成短流程,然后进而增加执行时间在任务中的切换频率。可以促进轻量级任务的提早执行和结束,也间接能够提高大部分任务的及时性。但对于原本又长又臭的任务来说,此类优化可能带来的改善并不大,同时还需要优化者对程序整体有一定度的把握。
3,任务分拆,这样优化方式是将任务的关联性和时效性做一个定性分析。将相关任务集中起来,不相关任务分拆开;并将任务流中的上下游进行松耦,接着再对相关的业务进行松耦。这样做的好处在于一切以任务执行为视角,进行分拆,可以有效的区分开重任务和轻任务。同样也可以定性的了解到即使性要求高的任务和及时性要求低的任务。缺点在于,优化者同样也要对整个程序有一定的了解。
4,框架优化。这个难度大,没有做太大分析。
因为1和2都是夹杂着代码上技巧性的优化,这种优化如果考虑不当很有可能事倍功半,反而降低代码的可阅读性和可维护性。之前,我就遇到过一些成天嚷嚷着“算法”的人在用“算法”的思维去优化代码,结果代码优化下来性能是有一定的改善,但可维护性和可阅读性就差到极点了。甚至优化者本人自己去维度代码也是满天飞的bug。
介于4这种都是构架师水平,我最终选择3。
从任务的关联性出发,将一些重任务,以及及时性要求高的任务进行分类,并把这些任务的旁路任务进行一同整理。最终得到几类任务:
1,一般任务
2,及时性高任务
3,重任务
其中一般任务继续保留在原先的单线程框架中。及时性高的任务会从中剥离出来,并挂在一个新的单线程框架中;后期随着这个单线程任务量的增加,最终线程会逐步调整代码中的线程数。
重任务,其中重任务也被挂在一个新的单线程框架中,处理方式与及时性任务的处理方式一致。只不过对于及时性高的任务,可能还需要做一些代码层面上的执行优化,不过应该不多。
通过上面的方案进行优化了以后,发现整个客户端任务执行的拖沓、任务切换的不及时得到了较大的改善。看来改善任务安排有时候比起用一些代码技巧更为重要。
当然,我在这里说说是很容易的,实际写起代码来未必那么容易。因为涉及到多线程,就需要留意任务的关联性。因为关联性的存在,就会出现线程资源竞争,资源出现竞争时,就会很容易出现数据不同步,死锁,野指针等问题。
这是就需要经验和一定的代码技巧来解决这类问题。因此合理调整程序结构与代码技巧同样重要,如果一味的追求代码技巧和所谓的“算法”,那最终会失去对整个程序的可持续维护和开发的可能。这就如我之前所呆的一家公司一样,软件在国内某行业里还是有点小名气,但是真的要去看代码的话…………………bug、可阅读性不是在人类可理解范围内。反而这个团队内总有人一味的强调“算法”、“二叉树”什么的,数据结构与算法确实是程序的核心之一的东西,但现在国内的公司并非科研机构,顶多只能算一个做的工程。多数时候其实以工程的思维就能把问题解决好的,根本没有必要上升到“算法”层面,再说了,代码都没写好装什么逼呢?