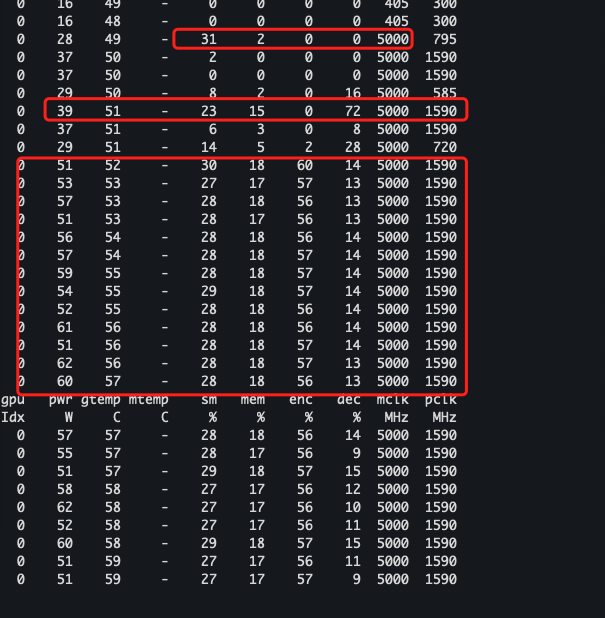
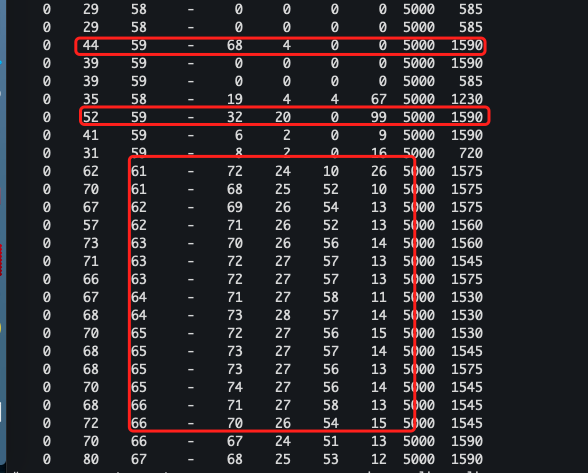
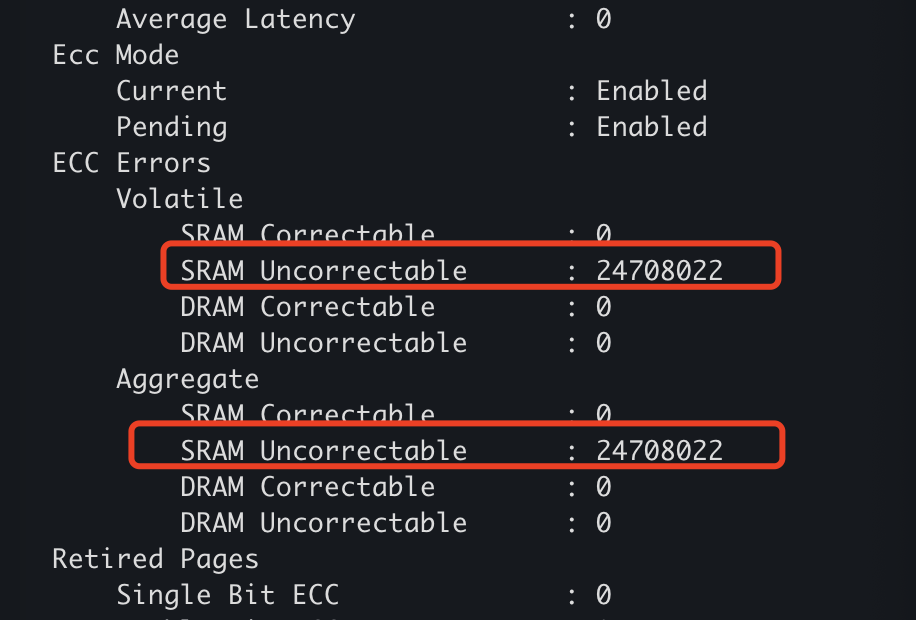
葫芦七兄弟故事(一)
首先提一下葫芦七兄弟这个标题的缘由,因为在2020年4月,本人换了一个工作,进入了某A公司(不是不爱钱的那人开的公司);这个公司在现阶段是在线实时音视频做的还不错的一家,无论知名度还是市场占有率,都确实到了一定高度。
选择这家公司的原因其实也蛮简单的,主要是想通过公司的平台,对自身的技术有个提高和成长。加入公司以后却看到的不是成长和学习,而是首当其冲的就是被拉去支援隔壁大部门的工作,接着就是被各种神仙之间掐架时候的各种有意无意的误伤(说白了就是拿我指桑骂槐)。
显然透过这样的工作体验是奇差无比的,况且这里面也感到了一丝丝各种奇奇怪怪的工作氛围。
入职到今天,已经经过了9个月了。最近听到隔壁部门在做一些人员架构上的变动,听到这个消息的时候,实际上心里是有些不太舒服的。原因是隔壁组的老大要换,而过来的老大就是当初就是“恶心”过我的人。
书归正传,为何会写这个东西?
还是相对自己目前的工作状态和心里状态做一个回顾和梳理,避免一而再再而三的出现问题,反反复复的出错。同时也便于做一些及时的心态调整和变化。其目的还是为了减少这些糟心事对自己的影响,也可以适当的让自己有机会和精力朝着自己的目标去进行。
为何这样取名?
因为组里有7个人,而这7个人各有所长,也各有自己的性格特点。所以叫葫芦七兄弟比较贴切和理想。
这七个人是什么样的特点?
在我心里,这7个人的特点:
- 老大,有自己的想法和目标,也有一定的能力,思维活络。但也许由于一些原因,又或许自身的性格特点,自己很少做一些团队工作方面的输出。或者说,在我眼里,在一些团队带领方面没有体现出管理者应有的素养(实际上很多管理者都没有)。我的新员工导师,导师这块我觉得还缺少了一些工作方面的引导(代码)。
- 老二,年纪不大90后。不太爱多说,性格特点比较主观,有一定自我或自负的情况,不通融,不豁达。工作技能有一些比我强的地方,但可能由于一些因素,或自身自负的原因,似乎并不以为然。
- 老三,年纪应该很大(应该是70后),似乎是做编解码出身的。起初打交道的时候,感觉还不错,能够提出一些正向且积极的意见和建议,但细细接触后发现,做事情有点拖沓,人水平不错。如果人能放下一些身段,踏实一些,不管是技术之路,还是管理之路,我相信都会不错很多。加上确实技术上有一定水平,我会很乐意找他做我的老师。
- 老四,我。脾气大,不喜欢得罪人,但也不是什么老好人类型;不愿意直接面对工作上的矛盾;同时是一个说话“啰嗦”的人(这里面分为有真的啰嗦成分,也有别人有意或无意找的接口!)。技术功底一般,技术技能比较杂,不想一直这样杂下去,想沉淀某种技术。对目前团队信任感缺失,不太想发言,或者说在等待能够把自身感兴趣的技术做下去做深的机会。
- 老五,其实老五和老六是同一天入职的。但后来听说老五本来也应该是4月份日志的,所以就区分开两个人了。老五是某不爱钱老板开的公司出来的,起初感觉还挺不错的,但后续不晓得是不是什么原因还是怎么的,总感觉老五做事会有几分此地无银三百两的情况;所以当时还在对老五做了一些留意和观察,对他还是尽量抱着友善的态度,但持续保持适当的距离。据说以前是做android media framework移植裁剪和维护等(搞android os里面),人技术应该挺不错的,但给我感觉做事目的性太强了,我有点怵,所以敬而远之。
- 老六,人其实挺不错的小伙的。就是给人感觉太爱表现了,说话做事有很多时候很喜欢信口开河,对技术了解不深不扎实的情况下,也会随便说出来。人本身也许没有太多坏心眼,但是太急躁没什么好处,有时其实我也挺烦和他打交道的,说话给人感觉很喜欢瞎指挥,太把自己当回事的情况,而且影响别人的工作效率;夹带私货(心)的时候有点多,成分也有点明显。有几次我真的忍不了,搞不懂他到底想要干什么,如果技术top1的话到还没啥好说的,关键是没到这个水准,做事的那股样子给人就一个大佬的错觉样,确实很难受。有很多时候,我并不想和这种人打交道,因为提高太少了。
- 老七,刚来。目前看上去还是挺谈得来的样子。和老大在同一个办公地点,最近活跃度降低了不少,预计身上事情在变多了。或者其他原因,后续再看。
今天先写道这里了,下一篇,我想重点写一写七兄弟,我对他们六个人的看法和感受,以及我所了解到他们可能对我的看法或感受。