前言
2022的计划,就是开始做个小工具,拿来分析es流,主要通过解码器解码es流,来获取编码中一些过程,比如预测方向,slice qp等等。当然也包括最基本的parser,虽然这块会有很多bug(只要是字节流相关的代码都很容易出现解析和打包问题)
所以现在最先需要解决的是ffmpeg的编译,然后再找一个稳定简易的界面库来先基本完成264的码流解析和解码工作。
脚手架选择
windows terminal
msys2
vs 2017
安装
略过
编译
配置
windows terminal
msys2
这里需要说明的是,msys2现在支持ucrt和mingw64两种链接方式,区别在于前者使用系统自带的crt链接到编译出来的库中,后者使用msvs的。目前还是继续使用mingw64的版本
#先更新一下
pacman -Syu
#库管理工具
pacman -S pkgconf diffutils
pacman -S make
#sdl2必须品
pacman -S mingw-w64-x86_64-nasm mingw-w64-x86_64-gcc mingw-w64-x86_64-toolchain
vs 2017
略
其他
关于ffplay的编译
由于msys2自带的sdl2包和本地vs编译环境可能存在一些不兼容的情况,所以有两种办法。所以需要单独下载sdl2编译后,再创建ffplay的vs工程来做。
虽然我一直都是将自身技能分为软技能和硬技能,并且按照一定规则来进行计划,不过还是有必要重新考虑一下侧重点,这么几年下年,折腾来折腾去,东搞搞西弄弄,一直没有很好的执行一个系统性或者专业化的自身知识技能体系。但维度有一点很明确的是,自身工作方向一定要和自己的目标知识建设是存在较大关联或重合的,这方面做的还是不错,所以大部分时间都没有跑题跑的太偏了。
硬技能
学历、院校、就职单位- 性格
- 江山难改本性难移,只能说尽量保持克制和改善。不忘初心也很重要
- 为人处世
- 最讨厌乌烟瘴气、帮派和小圈子,除非有必要,小圈子是一个不错的选择,但是小圈子很容易会和前两者有很强的关联性。还是需要一定程度上的假装合群
- 站队,不站队远比站队还严重。一直以来都不站队,或者抗拒站队,在一个比较强调控制的团队或组织里面,很容易被弄,最后过得也很惨,不过也从侧面反映了,这种团队和组织没必要长待,长久不了;事实却是证明了,不管多少年过去,这种组织或机构要么都死掉了,要么勉强维持着现状。
- 有时候少一点有意而为,很多时候明知道这样做的结果会如何。但自己偏偏不信邪,并且带着好奇心的故意做一些事情,反过来观察大家的反应,尽管确实很有效果,也相对客观准确的能观察到信息,但实际上不太理想,容易变成掘地自焚。
- 管理 & 洞察
- 尽管不喜欢也不想做管理岗位,也不愿意去做。主要还是不愿意和人打交道,不想去搞那些麻烦的人和事,也不想承当责任。
- 但事与愿违,年纪上去了,就该适当的考虑扩宽自身的路子。所以管理岗的一些同事,他们的行为风格是一个较好的学习习惯,和观察机会。透过他们可以间接学习一些成与败的经验。
- 从小到大洞察能力是不需要做任何评价的,这一个点是先天有优势,但还需要注意一下,不能让自身主观兴趣过多的去主导洞察的目标和信息的获取。先收集信息,后整理和分类。然后适当的对洞察结果做出相应,稳优先,切莫太急躁,因为现在认为干扰信息也挺多的。
软技能
- 知识深度
- 这里需要明确,这里提到的知识深度不同于公司层面,因为公司层面更多是通过所谓的知识深度来淘汰人的一个借口罢了。
- 这里更多是结合现阶段自身岗位情况,和未来目标可达岗位情况去指定的知识深度学习计划
- 编解码
- 目标:<了解>编码原理,能够通过码流的一些现象来判断大致的问题
- 知识范围(粗略,待二次细化):
- <了解> x264预处理过程
- <了解> x264图像分割的过程(预测、宏块划分)
- <了解> x264熵编码特点(非了解算法内部)
- <选择了解> x264 码控等相关模块
- check point(2-3年完成):
- 产出工具或matlab脚本,演示预处理过程
- 产出工具,可视化预测、宏块信息(先帧内,后帧间)
- 知识广度
- 这里需要明确,这里提到的知识深度不同于公司层面,因为公司层面更多是通过所谓的知识广度来淘汰人的一个借口罢了。
- 这里更多是结合现阶段自身岗位情况,和未来目标可达岗位情况去指定的知识广度学习计划
- 策略器
- 目标:搞清楚现有的一些策略器,对媒体“流畅”和“质量”的影响有哪些,如何做到的。
- 知识范围:
- <了解> 采集 <-> 前处理 策略通路
- <了解> 前处理 <-> 编码 策略通路
- <了解> 编码 <-> 编码 策略通路
- <了解> 编码 <-> 网络 策略通路
- <了解> 总控 <-> 各子控 策略通路
- check point(1-2年把大致流程搞清楚):
留意几类人
- 没自知之明,自以为是;关系不便搞僵,不过距离要保持住
- 自私的人,这些人靠利益维系
- 小圈子,小帮派。凡是”小“这个东西就很成问题
- 虚的人
- 看似很好打交道,其实很难的人
windows下调试代码,有符号表和没符号表在某些方面的开发,差别较大,尤其是和一些windows基础库或偏底层的相关性较大的部分。巨硬的符号表服务器访问比较慢,一般为了能够快速进入调试模式,都是提前下好符号表,下面是根据遍历本机所有exe、dll进行符号表匹配并下载的命令
symchk /r C:\Windows\System32\ /s srv*D:\sym*http://msdl.microsoft.com/download/symbols
这样做只能加快本机调试的速度,对于其他环境上的dmp解析,远程调试可能用处不大,主要取决于系统中各类库的版本是否和本机的一致。
作为一个写c++98写习惯的人,对于c++11开始新引入的一些修饰关键字已经有些模糊,尤其是override已出现,整个人就有点困惑,并且在平日写代码里面还是沿袭了c++98虚函数重载的写法,被同组的小鲜肉鄙视(其实他种种高傲又和自身水平不相称的行为,我是相当鄙视的!),问其原因又未告知。果断看c++11书先了解。
首先看看下面两种写法:
//写法一:
class A {
public:
virtual void A() = 0;
};
class B : public A {
public:
virtual void A() {}
};
//写法二:
class A {
public:
virtual void A() = 0;
};
class B : public A {
public:
void A() override {}
};
本质上上面两种写法并无太大差别,由于A这个类是纯虚类,子类只要存在有函数没有进行重载,编译阶段结汇出现报错,此时override在这里可有可无,区别不大。
但如果是下面两种写法,override就体现了作用
//写法一:
class A {
public:
virtual void A() = 0;
void A(const int a) {}
virtual B() {}
};
class B : public A {
public:
virtual void A() {}
virtual B();
};
//写法二:
class A {
public:
virtual void A() = 0;
void A(const int a) {}
virtual B() {}
};
class B : public A {
public:
void A() override {}
void A(const int a) override {}
void B() override;
};
- 由于带参数的A函数是非虚函数,仅仅可以通过“覆盖”的方式进行,而使用override进行修饰,将会报错属性错误。这样可以用来检查类继承时候,成员函数属性错误的情况
- 由于加了override,在编译阶段,写法二会检查B函数在子类中是否已经被实现,如果没有实现会报错。而对于写法一来说,只有子类的B函数被使用到的时候,才会在链接期进行检查。这样可以提早发现代码漏实现的情况。
奇偶数判断优化
一般情况下判断奇偶数都是用
if (0 == a % 2)
但可以优化为:
if (0 == a & 1)
取偶与取奇
有时候需要对一些数进行取偶,那么代码可以优化为:
取偶:a += a&1
取奇:a += 1-(a&1)
公司代码用了syslog,但由于一般公版的docker基础镜像里并没有syslog服务器。因此需要做个单独安装。
启动镜像后执行如下命令,即可完成syslog服务的安装和启动。
apt update && apt install rsyslog -y
rsyslogd
通过一下命令测试一下
logger "test"
在/var/log/syslog中出现了刚才的日志就说明服务安装成功。
由于某些不可抗拒的原因,要搞go,事实上我是非常抵制,主要原因还在于go的开发环境等都不够成熟,另外也没有必要非要用go,除了由于python的gil性能问题意外,其实c、c++、python就已经足够满足大部分开发需求了。就连音视频部分的绝大部分都已经能够胜任。
唉,在vs code中虽然配置看上去虽然简单,但由于go语言本身坑爹的编译环境加之vs code整体性不如vs,因此还是遇到不少坑。
坑爹一:在使用go调试代码时用到了dlv,非调试运行环境也最好用dlv,不要用code runner。
具体表现为,使用start without debug,不要使用run code。由于在gopath的问题上,code runner在go开发环境上本着能坑死一个算一个的目标,让人哭笑踢飞。
持续更新中…….
bool srs_is_little_endian()
{
// convert to network(big-endian) order, if not equals,
// the system is little-endian, so need to convert the int64
static int little_endian_check = -1;
if(little_endian_check == -1) {
union {
int32_t i;
int8_t c;
} little_check_union;
little_check_union.i = 0x01;
little_endian_check = little_check_union.c;
}
return (little_endian_check == 1);
}
通过上面代码片段可发现little_check_union的大小只有4个直接,通过访问最后一个字节来判断当前平台(软件+硬件平台)大小端情况。
同时也可以利用union来进行访问,这样的访问方式较直接安位操作来说简单性能差一些,但也只一种较为简便和安全的做法。(虽然不是绝对安全的做法)
在写代码的时候,有一些技巧和方法已经快成为成为了众矢之的,主要还在于代码的可阅读性,以及易错性上。
被列为经典的几种方法或技巧中有一些还是能用尽量少用:goto、递归、状态机。
goto
写过汇编的人都知道,汇编改变指令执行地址的方法里,除了call/ret,还有大量的jmp/sjmp来构成一个程序,如果仅仅使用call/ret来写,有时候代码会变得非常臃肿,而且让本来就难以理解的汇编变成更难阅读的代码,所以就会用jmp/sjmp来改变指令执行的地址。当然这只是抛砖引玉,在汇编里改变指令执行地址可不仅仅这两对指令,还有很多其他指令和方法。
而goto是我在学c语言的时候接触到的,c++也依然部分支持(具体看编译器和相应语言标准)。goto更像是汇编中变成思维的一种移植,类*inx系统的内核代码里也拥有大量的goto使用。
在面向过程变成里,使用goto似乎并没有太大不适,而且也能在一定程度上减少代码规模。但goto若用的不好,带来的效果适得其反。而且容易使得代码逻辑变得极其复杂,非常的绕思维。
goto在短小精干的代码里,可以较少的带来阅读和易错现象,而且要把goto用的好,用的巧妙,还非常考验写代码的人如何编排代码流程和排版。
若没有过硬的逻辑思维能力和计算机式的思维能力,goto能避免最好避免,尤其是在写一些对代码体积和性能要求不是太高的情况下。
代码的性能和体积其实可以通过其它方式优化,未必非要这样。
递归
在数据结构和一些基本算法的教学里,递归是用的最频繁的。因为一些解题思路用递归来执行比较接近人类的思维方式,更容易理解。
栈帧的维护和执行,也是通过递归的方式进行的;可见递归的重要性。但是递归还存在容易让栈空间溢出,以及无限递归的出现,同样也存在一些不便于理解代码的情况。因为每一次递归函数的重入,都会使用新的栈帧对象,导致局部变量不是同一个的现象,这恰恰很有可能会让人在无意间错会递归的过程。
若不是解决问题的模型比较接近递归或代码短小精干的情况下,能用别的方式化解递归,最好通过其它方式。
状态机
状态机是一个基本的原型机或记录器,要从时间的角度出发讨论,状态机应该最先出现在高频模拟电路里,一些信号同步机制与触发应该是最接近状态机思维。
只不过后面称做状态机的都是从数字电路开始,状态机在设计门电路时,是最好用的一种分析工具或辅助工具。但在协议栈、驱动、直接和硬件交互的代码里,往往有着很多的状态机。
状态机由于仅仅是表征一种状态跃迁并联系成一个系统的工具,并未对状态跃迁的规则做约束,因此状态机很有可能会被设计的非常复杂,详情可以参考协议栈代码。若是过于强调状态机的特性,在写一些复杂度较高的策略模型时,往往是容易简单问题复杂化,甚至力不从心。
建议将状态机解耦,改为状态化就好。接触每种一状态之间的耦合度,会让代码较为简单些,如非常强调性能,可以通过其它方式解决。
最近在ios上出现将多个sdk放到一个app时,有各种开源静态库冲突的问题;于是考虑将自己用到的库进行打包成动态库版本,以此解决冲突问题。
在进行打包成动态库时,发现x264问题最大。打包出来的库在链接期出现text relocations错误,网上找了以后发现基本都是进行忽略这个错误,事实上这个错误忽略了没用,app启动时还是会出现相应的crash。
换了几个版本的xcode进行测试,发现x264编译会出现不同情况的告警和错误,根据底部罗列的参考文章,估计xcode的编译器可能也有一些bug。
后来模仿android上的编译方式,在x264里加入了–enable-pic和–disable-asm顺利编译通过,但由于osx和xcode版本的因素,模拟器上的并没有编译出来,仅仅编译了armv7和arm64。
参考文章:
MacOSX下编译linphone(text-relocation错误说明)
libxxx.so- text relocations问题的终极解决方案(android)
Linker error when using incremental builds on iPhone
Android Gradle编译so库或运行时出现 text relocations 崩溃的正确解决方法
设计模式一直给我的感觉都是天书一样,一方面理解起来困难。另一方面书上的解释也较为枯燥,况且现在也还有很多号称设计模式大神的出现,也可能间接的让大家对同一个模式有了各种千奇百怪的理解。
设计模式这个东西出现初衷本来就是解决工程问题,而在解决工程问题时,每个人的角度不同,观点也就不同,并且在《head frist 设计模式》中,作者也强调过,没有任何一种模式的选择和使用是正确或者错误的,只有适合与否。同时对设计模式理解有偏差,甚至初学者也才会去讨论某某模式好,某某模式如何。对设计模式理解较为全面,工程经验较为丰富的人,只会说某种模式用起来较为自然。
代理模式可以的重点可以看作主要是屏蔽了实现细节,同时也对任务执行做了一个中转。让两个模块之间进行解耦。
例如一个消息队列的实现,对于消息队列来说,实现可复杂可简单。为了让消息队列的使用者能够更清晰的了解如何使用,首先需要对消息队列的一些内置方法进行屏蔽,在C++中,继承是无法做到这一点的,所以只能通过包装的方式来实现。
因此就产生了代理类来将消息队列的实现类进行包装,让消息队列的使用者更加关注与如何使用,让消息队列的实现者来关注如何实现,而对于代理来说,仅仅需要关注如何流转数据和流程即可。
先看如下代码片段
#include <vecotr>
#include <string>
#include "boost/algorithm/string/split.hpp"
#include "boost/algorithm/string/classification.hpp"
#include "boost/algorithm/string.hpp"
std::vector vStrArray; //里面存着一堆字符串,其中有一个字符串是这样的: " a.kbasdasdsad"
for (auto a : vector)
{
boost::trim(a);
}
#include
#include
#include "boost/algorithm/string/split.hpp"
#include "boost/algorithm/string/classification.hpp"
#include "boost/algorithm/string.hpp"
std::vector vStrArray; //里面存着一堆字符串,其中有一个字符串是这样的: " a.kbasdasdsad"
for (std::vector::iterator a = vector.begin();
a != vector.end();
++a)
{
boost::trim(*a);
}
编译环境是vs 2015 update 3
分别执行完以后会发现,A代码片段没有任何变化,B代码片段的” a.kbasdasdsad”变成了”a.kbasdasdsad”。
单步的时候发现,a变量在A代码片段中,实际上是已经对被修改了。后来网上查了几篇资料,怎么也没有找到对auto的详细说明。加上c++ 11每个编译器实现可能存在一定的差异,因此只能认为,在auto修饰的for循环里,变量使用了写时复用的方式来处理。
如果要对vector里面的值进行修改,还是只能使用最原始的迭代器方法。
最近osx环境无意间升级了所有的包,并把xcode升级到了9。按部就班的继续编译之前可以正常编译的webrtc,后来不料,除了这么一个错误:
error: nullability specifier ‘_Nullable’ cannot be applied to non-pointer type ‘uuid_t’ (aka ‘unsigned char [16]’)
东查西查。最后就查到了之前的猜测,这里有解释:
https://forums.xamarin.com/discussion/103773/will-there-be-support-for-ios-11-sdk
因为xcode自带的是ios sdk 11的。就目前来说,这一点比较坑人,因为ios sdk 11的库和ios sdk 10的库在部分函数上的定义上有所区别。
而webrtc和相应的depot_tools也是今年年初的,因此使用的第三方clang编译器也相对xcode 9的步调来说老了一些。
为了不想增加麻烦,也就不打算用gclient了,因为当时不是我去拿的webrtc代码,也不知道会不会有坑。就果断把xcode降级为xcode 8。
xcode 8的下载地址:
https://developer.apple.com/download/more/
降级的方法:
http://osxdaily.com/2012/02/20/uninstall-xcode/
看来用第三方编译器也是让人比较头疼的一件事情。有时候ios上遇到的坑不比android少。。。
在编译x264和ffmpeg时会出现警告,截图如下:
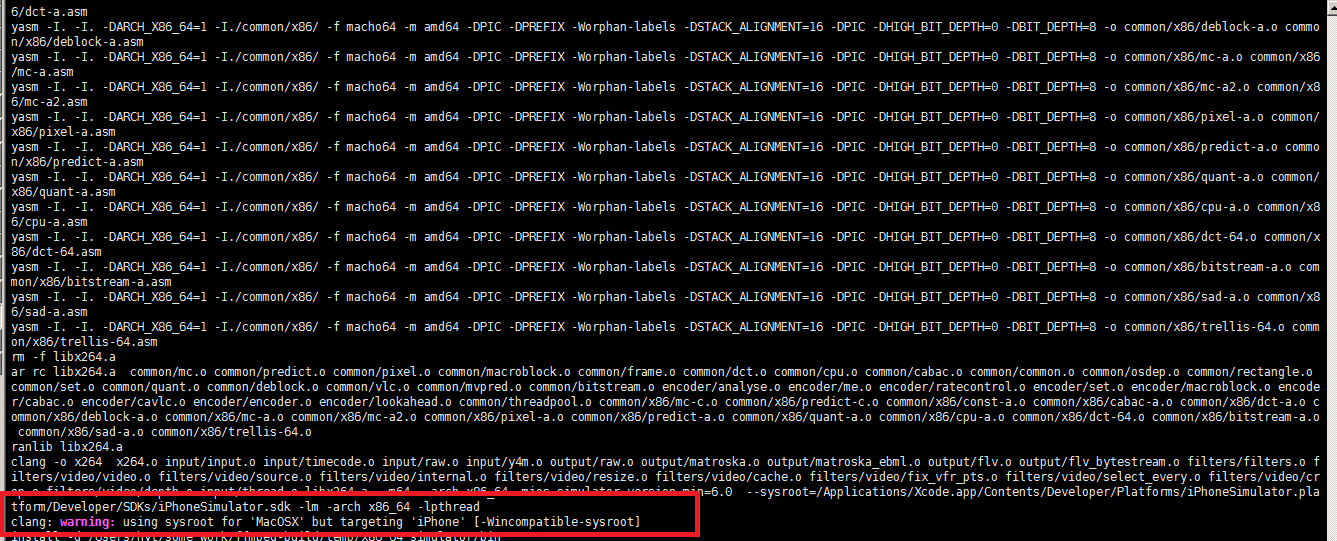
实际上在命令行中已经看到,已经通过sysroot设置过目标平台的sdk的位置,但还是报错。通过google发现,新版本的xcode对sysroot参数关键字做了修改,将–sysroot改为-isysroot ,其他不变,编译通过。
由于最近使用的ffmpeg及其相关的库太过于老旧,所以需要进行更新。
对于视频方面的编码主要用到h264,音频则用到mp3、aac、speex。
其中最为坑的,还是mp3和aac。因为mp3中的分支太多,为了简化问题,最后还是选用lamemp3作为编码器。在ffmpeg 3.0开始,ffmpeg就停止了aacplus的使用,改为使用fdk aac。并且ffmpeg还自带了一个aac编码器。
在编译过程中由于没有注意到这个问题,因此使用了内置编码器,导致he aac编码出来的数据缺少sbr段。因此需要外部加入fdk aac来完成。
1、lamemp3源代码
2、speex源代码
3、fdk_aac源代码
4、x264源代码
5、ffmpeg源代码
6、安装msys2极其相应的工具(如果在windows上编译)
7、vs2015(如果在windows上编译)
lamemp3编译步骤:
直接代开源代码下vc_solution目录,使用vs2015编译即可
speex编译步骤:
打开win32目录下的vs2008直接用vs2015编译即可
fdk_aac编译步骤:
fdk_aac编译比较坑,不能在msys2中编译,需要用nmake(vs工具链)直接编译就好……
x264编译步骤:
在msys2中直接编译即可
ffmpeg编译步骤:
1,将speex、mp3、aac中include的部分代码拷贝到ffmpeg根目录下
2,在将相应的lib文件拷贝到根目录下的某个文件,这里用3rdparty来代表目录
3,执行编译命令
./configure –prefix=/c/work/github/ffmpeg_src_3.2/out –toolchain=msvc –enable-libx264 –enable-libmp3lame –enable-libfdk-aac –enable-nonfree –enable-libspeex –enable-gpl –extra-cflags=-IC:\\work\\github\\ffmpeg_src_3.2 –enable-shared –extra-ldflags=-LIBPATH:C:\\work\\github\\ffmpeg_src_3.2\\3rdparty\\lib
4,执行make和 make install之后即可