【vs2013、msys2】vs2013命令行环境变量不继承到msys2
编译一些开源的时候不得不需要用到msys2。所以需要现在vs2013的命令行环境中启动msys2环境,这样就可以把vs的命令行环境变量继承到msys2。
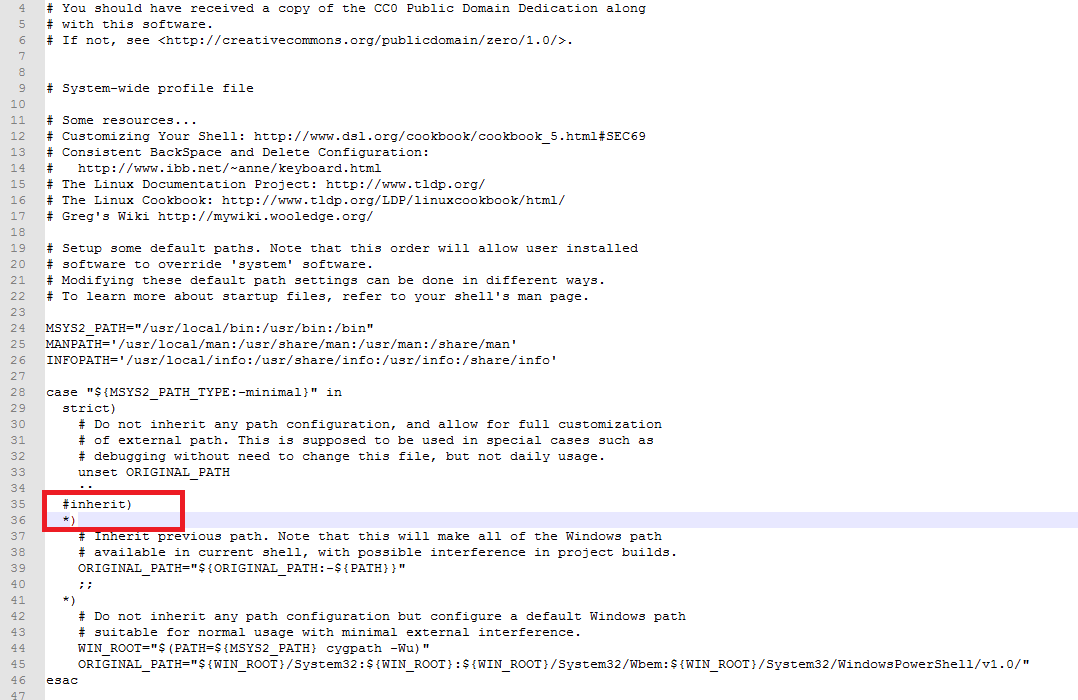
目前最新版本的msys2会出现不继承的情况,主要由于msys2 中/etc/profile文件中继承脚本的过滤了vs的一些有效环境,参考csdn上一个博客的修改方法,修改成如下:
编译一些开源的时候不得不需要用到msys2。所以需要现在vs2013的命令行环境中启动msys2环境,这样就可以把vs的命令行环境变量继承到msys2。
目前最新版本的msys2会出现不继承的情况,主要由于msys2 中/etc/profile文件中继承脚本的过滤了vs的一些有效环境,参考csdn上一个博客的修改方法,修改成如下:
webrtc最近半年的时间里又改代码框架,又改下载脚本!真***法科!
目前除了使用到python-curl、git、还用到了一个叫做python-boto的玩意,用来从aws上下东西的。不理解为啥不用自家的云。。。。
现在拿webrtc的代码,除了需要配置git、python-curl的代理,还需要配python-boto的代理。
python-boto的代理配置方式如下:
1,在某个目录中创建一个.cfg后缀的文件
2,然后填入内容如:
[Boto]
proxy=127.0.0.1
proxy_port = 10808
3,命令行中输入!
NO_AUTH_BOTO_CONFIG=C:\work\depot_tools\boto.cfg
最近在看webrtc的trunk上最新的代码,今天无意间留意到了stl容器中的“std::vector<T>::emplace_back”。事实上在接触webrtc之初我就经常能看到这个方法的使用,只不过那时候的对webrtc完全不了解,所焦点都在webrtc是个什么东西上。
后来查stl官方文档,看到的解释为:
构造并插入元素
同时网站上也给出了列子,但并不是很明确。看vs2015中对该函数的实现,实在看不懂(因为和push_back的一个分支实现很非常相似)。google看到这个函数代表在vector内部进行构造并放到数组里。
这样做的好处在于不需要去特意写移动构造函数,也不需要进行任何移动操作。间接的加快了性能。
ps:由于网上的说法存在问题,所这里要明确更正一下。
emplace_back和push_back两个函数都是通过“布局new”的方式将元素对象的内存放到自己的堆中(并非栈中)。
在最近webrtc的几个版本里,我一直尝试在windows上搭建编译环境。因为用惯了vs 2010,并且vs 2010之后的版本存在一个xp runtime的问题,所以一直想在vs 2010上编译。但是用不行,一直报错。
最近在看c++11标准,对比vs 2010 、vs 2013、vs 2015之后发现确实在c++11的支持上,vs 2015会更全面一些,所以最终还是只能用vs 2015作为编译环境来使用。
首先看一下下图,下图是stun或者说是NAT穿越时需要用到的NAT检测服务器拓扑组网图:

目前,PC B和PC A需要进行p2p连接,首要要知道他们所在的网络是呈现哪一种NAT类型。因此就涉及到了NAT检测服务器(stun服务器)和客户端。
NAT检测服务器的功能实际上很简单,就是自身拥有2个或2个以上的IP,并每个IP监听至少2个UDP端口,一共就有4个可连端(即4个socket)。
当客户端与NAT服务器进行通讯时,NAT服务器和客户端都将会知道客户端外网IP:Port,和客户端内网的IP:Port。
但在实际设计NAT检测服务器时,就遇到了一个问题:NAT服务器是否需要记录客户端的IP:Port信息。如果需要记录出于什么目的?如果记录那需要多少存储能力和计算能力?
首先分别讨论一下存储和不存储的情况。对于存储客户端IP:Port信息来说,可以有效的统计和判断当前客户端群(带了个“群”字样)的NAT情况,并且能够间接节省掉一个统计数据上报的过程,数据的及时性和有效性也得到了保障。但带来的是服务器程序设计上的复杂性和性能损失,带宽成本相对于不存储的来说或许会更低一些。
对于不存储的情况来说,客户端可以设计的很简单,并专注于NAT类型检测的任务,单点抗压能力可以发挥到最大;但带来的是数据统计与反馈方式需要另辟蹊径,增加了客户端的复杂度,某种程度上来说会增加带宽的支出(需要将IP:Port数据上报)。为了该工作还需要配套一个完整的数据统计与上报模块(服务端+客户端),某种程度上增加数据反馈的不可靠性。
在看新版本webrtc的p2p模块时(nat检测服务器),发现服务端并不存储任何客户端的信息,只是由客户端来自行决定是否存储。于是想到了这个问题。
对于NAT服务器来说,确实不应该存储过多的客户端信息,但如果在需要可靠性较强的环境中时,NAT检测服务器还是存储一定的客户端信息。并将一些服务器不需要做的计算和存储工作保留在客户端可以有效的达到合理使用的目的。
例如:在NAT检测中,往往会出现两种情况,即:
1,多级NAT中的NAT在不同时间段呈现不同的NAT类型(不规则NAT)
2,在单级NAT中,由于IP、Port限制型场景中,由于检测次数的不够充分,将IP:Port误判断成其他类型的NAT。
在这两种情况中时,需要进行定量或者定性统计分析时,如果数据仅仅保存在客户端时,由于样本不够大(NAT检测次数不够多、该局域网内可能不只一个客户端),导致分析不充分,进而影响NAT穿越成功率以及间接影响分享率、分享公平性。
所以需要将此类数据进行服务端统计,并作筛选,才能有效的判断出该NAT环境下较大的概率会呈现哪一种NAT。
在看webrtc的代码时,遇到一个ip地址池在set和vector中颠来倒去的代码,顶着看了一会,后来才反应过来。代码如下:
std::set<rtc::SocketAddress> addrs(all_servers_addrs_.begin(),all_servers_addrs_.end()); all_servers_addrs_.assign(addrs.begin(), addrs.end());
原先在all_servers_addrs_中已经保存了一个ip列表,通过导到set之后,首先去重了ip,接着再按照’>’算术运算符来进行排序,接着在通过assign将排序去重后的数据返回vector。
这样做的好处在于,时间复杂度为set排序复杂度+set随机访问的时间复杂度的总和,大致可以避免vector(类似线性表)的较高插入删除复杂度的问题。
最近一直在通过远程桌面的方式使用笔记本,突然发现matlab死活都打不开,出现如下错误
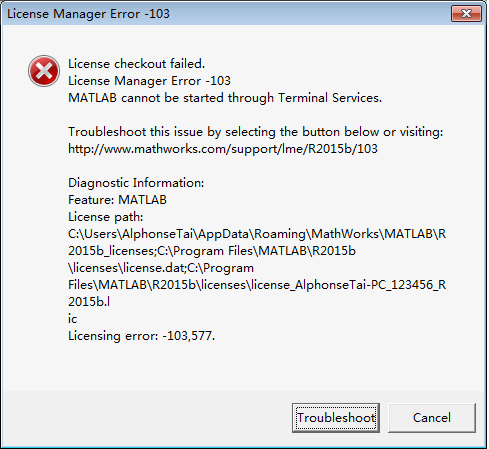
起初以为安装出问题,后来网上看了下才知道是远程桌面的锅。直接用基本登录,问题解决。
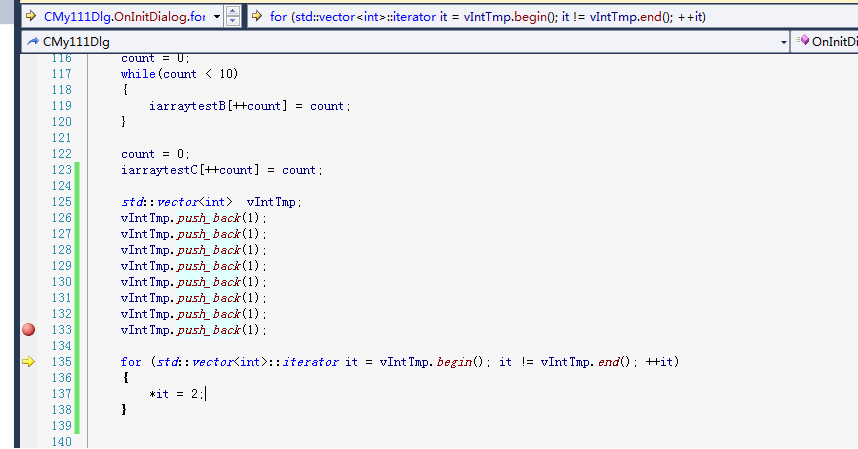
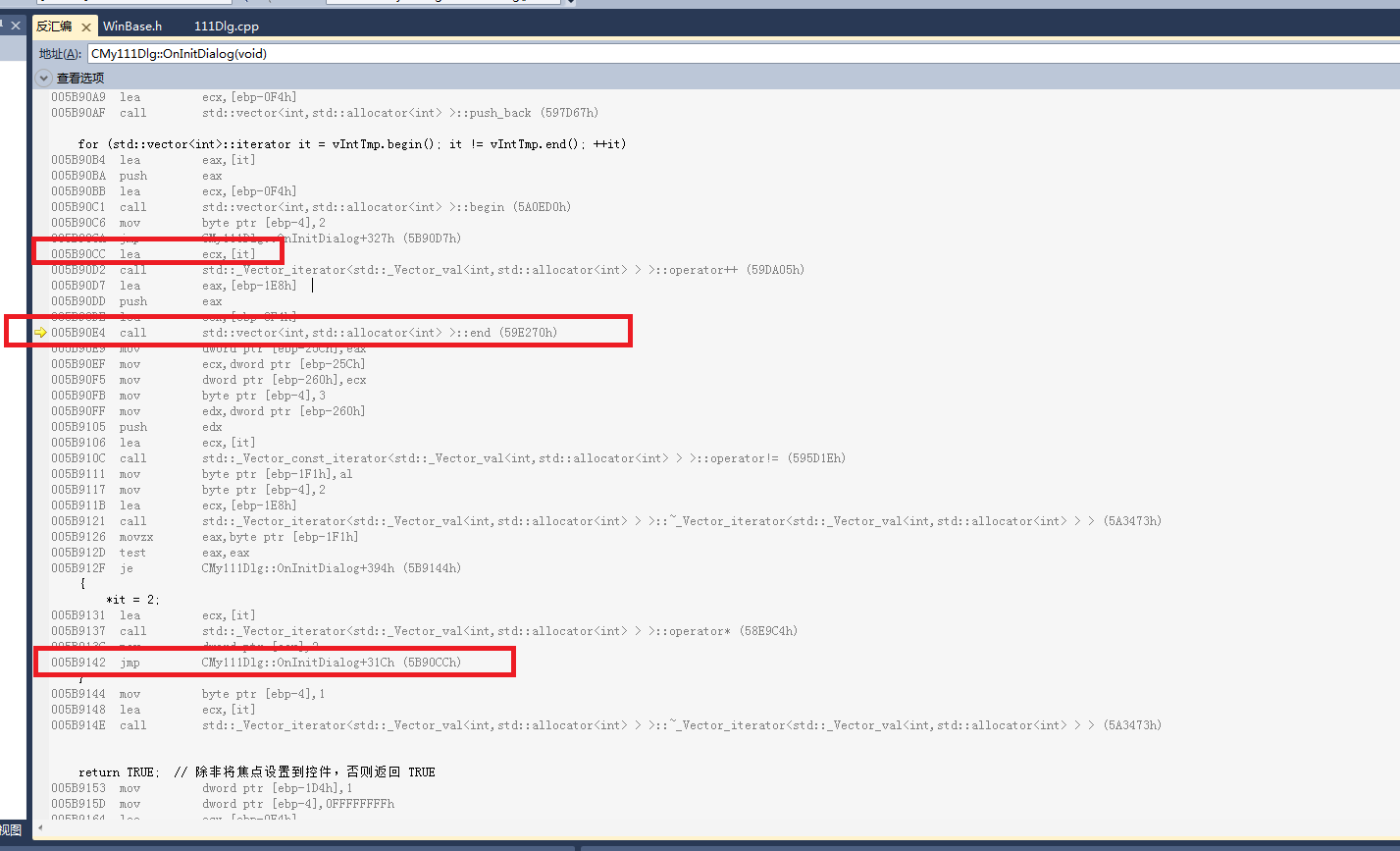
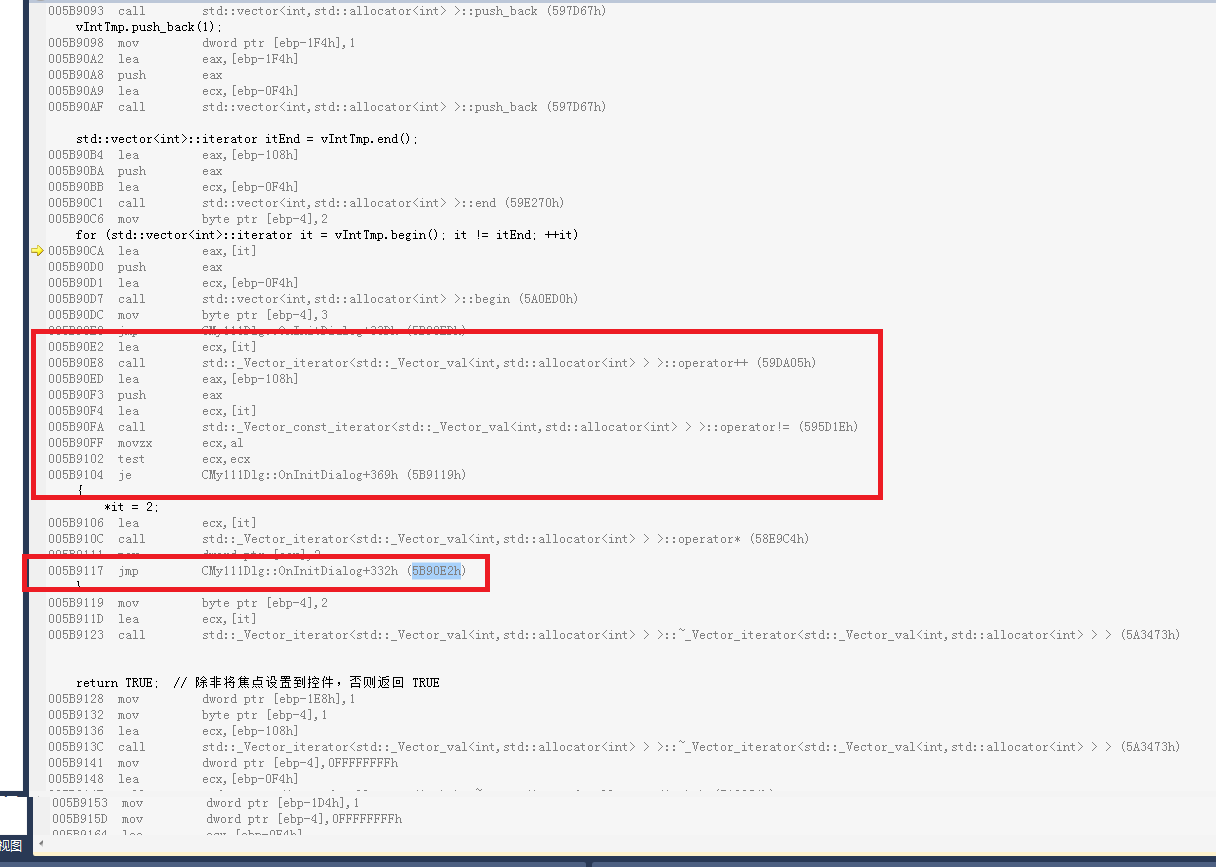
首先先看一下下面两段C++的代码
这两段代码唯一的区别在于条件区域的代码不同,一个是在外面先把end的游标获取到,一个是在for执行的过程中动态获取。如果实在想不明白,那就直接上汇编把。
实际上在《高效C++》中就提到过关于for条件区域代码每次哪一种写法性能好,哪一种写法性能差。由于end函数在这里的性能开销可以忽略不计,但如果不是调用end而是调用一个性能开销比较大的函数,那么这个for循环会很慢;在多线程模型中,如果for中的条件区域代码是线程间需要同步的,那么有可能这个条件区块代码的执行结果在每一次循环时都会发生变化。
对于这种代码级的优化,实际中最好少用或者不用,但并不是不带着优化的思维去写代码,而是在写的时候就要意识到这块代码可能会成性能瓶颈。
首先说明,本文章讲述的是C、C++方面的奇葩类笔试题,之所以奇葩是因为没有考到C、C++中真正需要关注的部分,也间接能看出出题人对C、C++的了解层度。
最近在外面试,有做笔试,也有不做笔试的。因为工作有一些时段,所以不做笔试也算说的去,但一遇到做笔试题往往弄得我哭笑不得。不是拿一些太基础的题来糊弄人,就是拿一些技巧性的题目来糊弄人。最为关键是招聘方所谓的技术人员还很自以为是。面试应该是互相尊重的过程,而不是耀武扬威的一个过程,下面就分享这么一题笔试题,也算是复习一下我自己的基础。
int count=0;
int iarraytestA[10] = {11};
int iarraytestB[10] = {11};
int iarraytestC[10] = {11};
while(count < 10)
{
iarraytestA[count++] = count;
}
count = 0;
while(count < 10)
{
iarraytestB[++count] = count;
}
count = 0;
iarraytestC[++count] = count;
求iarraytestA和iarraytestB的结果。用vs跑了一下,结果一样:
iarraytestA:0,1,2,3,4,5,6,7,8,9
iarraytestB:11,1,2,3,4,5,6,7,8,9
iarraytestB:11,1,0,0,0,0,0,0,0,0
后来仔细想想,这个应该是算术优先级的问题。这里面的符号有几个:
赋值、自增(前向和后向)、数组寻址
查了一下符号优先级表,发现++运算符的优先级和[]一样,而=的优先级就不用多说,应该是最低的。
由此可以得出上述结论。
首先在这套题里,主要考了笔试C、C++中对这几个符号的认识,另一个这道题最蠢的还在于使用了不该用的技巧在考人。在C、C++规范中对相同优先级的符号做过的约束并不是很明确(C++11有所改善),在高效C++中有大量例子说明不应该使用技巧性过强的写法,这样会导致不同编译或不同编译参数编译出来的代码有不同行为。
这也同样说明了出该笔试题的人对C++也不是那么了解,真正在C++中笔试中有很多类型的题目可以出,但也不是都能出,因为语言规范的原因,对于单纯考算法的问题,也有很多大神做过讨论。我只是觉得学以致用,考什么都不要紧,关键和工作实质内容有没有关联?
ps:另外强烈鄙视钓鱼招聘,叫人过去面试就是为了打探技术方法和商业信息!
当用c/c++做浮点数转换成整数时,处理一般都很简单,丢掉小数位置保留整数部分(没有看过具体的汇编,不清楚如果浮点数表达的位置太大,以至于整数溢出的情况)。
而在matlab中,浮点数转换成整数时候,会有四舍五入的规则,即:
uint8(0.499) = 0
uint8(0.5) = 1
所以在用matlab时,需要注意到数值转换与c/c++的不同。
最近在看心理学的大学教材,起初动机主要是为了了解自身,以及能够了解他人。不过越看到后面,感觉研究人的心理也越有意思。
可能是成长的过程中,恰好遇到了一些正确且有恰到好处的信息,或者出于自身性格的亲和力;再看心理学这门教材时,发现尽管有时候自身走了错误的路,但至少有能够自己纠正回来。并逐渐养成某些看似很难的好习惯和好规律。
例如:
1,很多人都说我很多事情搞那么清楚做什么,你活着累不累。
2,试着反思过去
3,试着窥视未来
4,试着察言观色
5,试着调整自己的心态和计划
6,有规律的作息和行为
7,设立底线,并针对不同环境和不同时期进行不同的调整
8,改善自身心态的同时也在调整自身的一些行为。
实际上,通过以上8个方面的行动,这其实是加强自我意识与自我认知;在日常行为中能够很好的做出一些反应和应对。我也庆幸,遇到一些问题时,我没有选择逃避,而是硬着头皮解决并得到了成长。
尽管通过学习心理学的书以后,自身的很多行为和想法,得到了一些说明,并且能够通过“规律性”的东西去评价行为的后果,但实际上最近心理还是在犯嘀咕;是该回头看一看了。
按照惯例,还是从工作、生活两个角度入手。
— 工作 —
1,可信赖人越来越少:
1.1 由于性格因素,导致原先可信赖的人在逐渐远离自身,且这些人本身原来就不是100%可信赖
1.2 公司环境混乱,导致大部分人心态发生变化
1.3 本来就没几个可信赖的人
2,对前途有所迷茫:
2.1 不理解现在做的事情对未来的职业规划有何作用
2.2 不确定的事情太多
2.3 领导层完全有意或无意不讲清楚意图,导致无头苍蝇状态
2.4 劳动力市场变化太快,有时候跟不上。所谓的“风投”太喜欢造势了。
3,过度消耗生命:
3.1 想学习
3.2 神经紧张,怕多休息或多娱乐一分钟,就被淘汰
3.3 想换一个环境
3.4 有所压力和追求
3.5 工作在消耗生命
4,总是在试图理解或揣测领导层的意思,但又不明白到底有没有必要,身心都很累。
— 生活 —
1,暂时没有进入正轨,还有很多事情需要硬着头皮去解决掉
2,缺乏良好可持续的规律或习惯
3,想要的生活和现在的状态存在一定的不对应或者不一致的情况
通过上面的情况,可以看出,最近应该在处于弥漫与焦虑中。或者把手头给自己安排的事情抓紧一点,或许能够更快的走出这种状态来。毕竟有一些事情其实已经规划好了,只不过还未到时候,加快步伐可以让时机提前到来。
下面图分别简易说明三种较常用的任务处理线程模型。
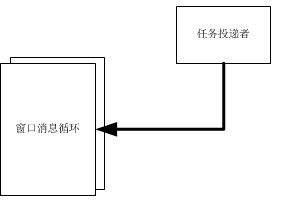
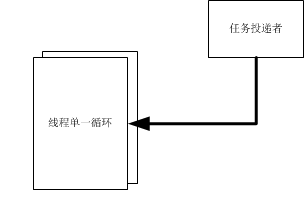
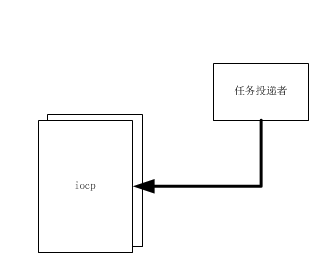
先说说为什么会来比较这三种任务线程模型,主要还得来于Chromium和手头工作中实际运用的特定问题;这三种任务线程模型在Chromium base的message_loop中都有过实现,且均用在不同的模块中(尽管message_loop中有大部分代码和boost中很像,或者就说直接拷过来的)。不过还是有必要值得讨论下这三种任务线程模型的特点。
这种模型构造最为简单,除了循环线程外,一般由一个临界、一个事件、和一个可以存放任务的数组或者stl容器组成。
但只可以同一进程内使用,或者经过内存映射后的跨进程通讯(一般没人这么干)。
任何任务的投递均要经历:
1,获取临界
2,往任务池中投递任务
3,激活事件
循环线程一般流程:
1,获取临界
2,取出任务池中的任务/等待事件激活
3,处理任务
对于循环线程可能会产生态变迁位置:
1,获取临界(虽然临界是用户态对象,但有可能会导致线程挂起等) —> 用户态转内核态
2,等待事件 —> 用户态转内核态
3,事件被激活,线程准备恢复执行 —> 内核态转用户态
总结:简单,态切换较少,且可能存在较大的线程时间处于用户态。速度快
*对窗口消息了解不是很多,所以这里只说一下仅有的少量了解。
这种模型构造组成:窗口、消息循环线程、其他辅助(例如要传递一个大内存,可能会用到共享内存等)。
特点:了解windows消息机制就可以用,且可以方便的处理一些和windows消息有关的任务,利用窗口消息分发特点可以很容易的划分任务类型。跨进程。
任何任务的投递均要经历:
1,获取窗口真实句柄
2,投递消息给窗口
循环线程一般流程:
1,等消息
2,取消息
3,分发消息
对于循环线程可能会产生态变迁位置:
1,等消息 —> 用户态转内核态
2,取消息(可能会出现,因为消息队列是用共享内存实现的,不清楚要不要做加锁操作) -> 用户态转内核态
3,分发消息(可能,由于一些消息是默认windows消息,或者是消息钩子链上的消息,需要把消息丢回消息链上,让其他进程进行处理) —> 用户态转内核态
*对iocp了解不是很多,所以这里只说一下仅有的少量了解。
这种模型构造组成:iocp模型、循环线程、其他辅助。
特点:可以方便的处理io相关的任务,内核态会创建一定量的线程数与用户态对应,需要做多次软中断;可跨进程。
任何任务的投递均要经历:
1,获取完成端口真实句柄
2,投递完成端口事件
循环线程一般流程:
1,等事件
2,取事件
3,处理事件
对于iocp线程可能会产生态变迁位置(实际上不全,因为在内核态还需要进行一次APC级别的软中断,iocp这种模型的一个任务流转过程,中断很频繁。详情请参考深入理解windows):
1,等事件 —> 用户态转内核态
2,取事件 -> 用户态转内核态
3,处理事件
由于手头有份代码,当初的作者可能为了简单或者什么原因,借鉴了boost的iocp模型,并形成一个单线程的底层驱动模型。
早在一年前,刚好要在这个模型上面添加一个及时性要求比较的功能时,发现任务处理的及时性不稳定。有时候任务处理很及时,有时候任务处理延时很重。每个任务的消耗都尽量保持在一个相对平均的水平。
在该模型中频繁堆叠较重的任务后,发现原来是该模型任务处理性能不稳定(被测电脑也是个性能较差的电脑)。后来将及时性任务从该框架中剥离出来以后,问题得到了较好的缓解。
最近在boost,刚好手里有代码,就做个简单的测试。简易代码在这
![]()
![]()
其中77s对应的图是release下iocp模型,空转1亿次的耗时
其中46s对应的图是release下简单线程模型,空转1亿次的耗时
可见如果只是比较简易线程和iocp模型的话,简易线程的性能会比iocp快不少,但由于特定使用情况,也不能过分的教条。
好像从vs2010开始,vs自带的max宏就不再被推荐为C++中使用的首选,而是尽可能的改为std::max这个模板函数。
在effective c++中也讲到了max宏和std::max之间的差别(但有时使用起来,还是不如max宏来的方便,尤其是当max的入参不是同一个类型时。)
好了,说正事。
在vs2010中,std::max被定义为一个模板函数,其中函数的参数类型推导主要依赖于第一个参数;且std::max被inline修饰。在vs中,inline的强度并没有forceinline那么强,因此编译时,编译器即可能会让模板函数展开,也有可能不会让模板函数展开。
有时候有些开源项目中,大量的使用了std::max,这也会进一步的导致编译速度减慢,编译出来的文件变大;这里面除了inline还有一定的原因和模板的特性有关。
为了解决这类问题,有事不得不做出一些折中或妥协。即,当杜写一个公共函数,在该函数中将std::max进行特例化,以此来达到优化编译的目的。假设在不调整诸如fpo之类的优化参数时,编译器都会一定只会将std::max进行仅有的有限次实例化,且也可以控制函数是否进行inline。编译时不仅加快了编译速度,同时也减小了编译输出文件的大小。
所以在一些实际项目中,如果对编译产出的要求比较高,有时不得不牺牲代码设计和可阅读性来达到目的。
今天把工程全部转换成了vs 2013,主要是通过vs2013下的一些动静态代码检查功能。转换成vs 2013以后,发现编译器的检查更加严格了。一些警告会被视为异常,例如:
OSVERSIONINFO sInfo; sInfo.dwOSVersionInfoSize = sizeof(sInfo); GetVersionEx(&sInfo);
这段代码在vs 2013默认语法检查规则中是编译无法通过的。
查看msdn对GetVersionEx的说明(https://msdn.microsoft.com/zh-cn/library/ms724451(v=vs.85).aspx)
[GetVersionEx may be altered or unavailable for releases after Windows 8.1. Instead, use the Version Helper APIs]
该api由于不安全,在windows 8.1中会有一组函数进行对其替代。同时,对stl和编译预处理的检查将开始更为严格。后续需要对windows 8.1的api和之前windows的api进行差异性了解。通过可得知vs 2013的设计就是为了操作系统而准备的,有意或无意的改变程序员的部分编程习惯。
代码段如下:
#ifdef TEST_FLAG
#define MACRO_TEST_1(x) OutputDebugString(x)
#else
#define MACRO_TEST_1
#endif
static TCHAR g_all[] = _T("test_for_macro\r\n");
TCHAR* test_for_macro()
{
OutputDebugString(_T("call test_for_macro\r\n"));
return g_all;
}
当 TEST_FLAG 被定义和未被定义时,将会出现运行结果。
其实这个是一个老生常谈的问题,关于编译器在对宏的处理情况。
如果堆栈数据空间地址被恶意或无意的修改,导致执行了不该执行或数据段的二进制值指令叫做溢出攻击的话;这类宏的情况,在某些情形下也属于宏攻击。