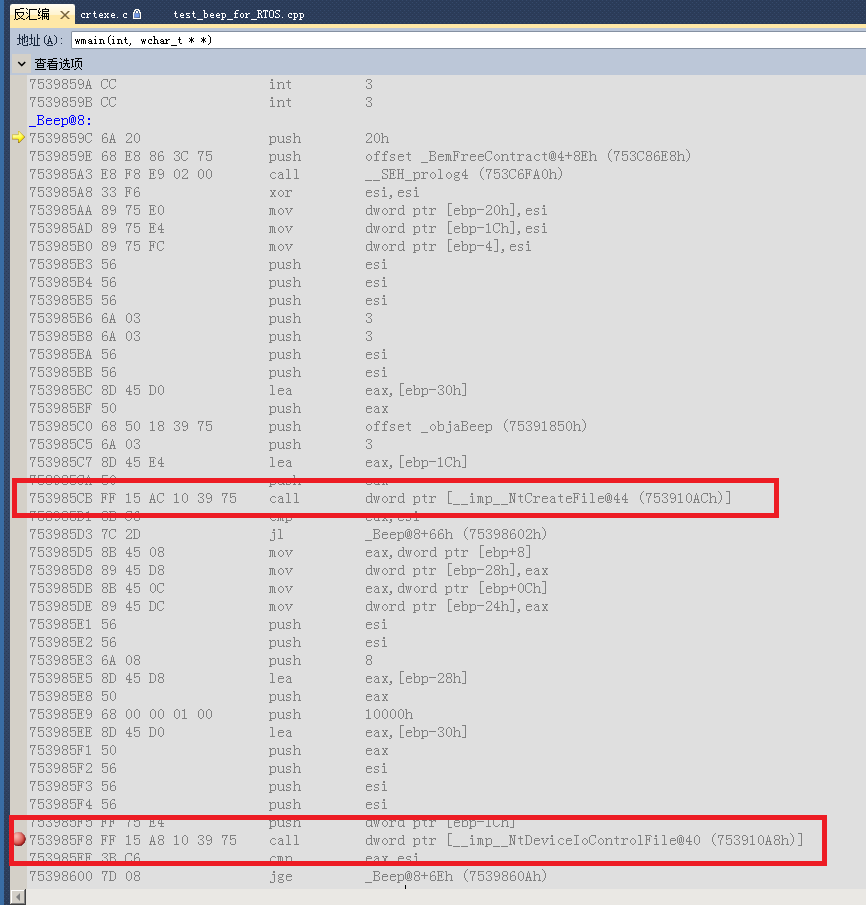
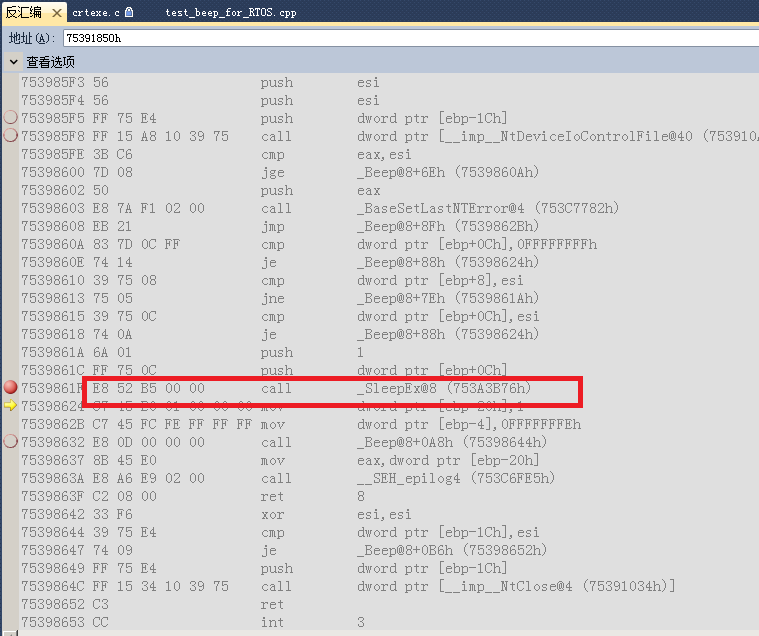
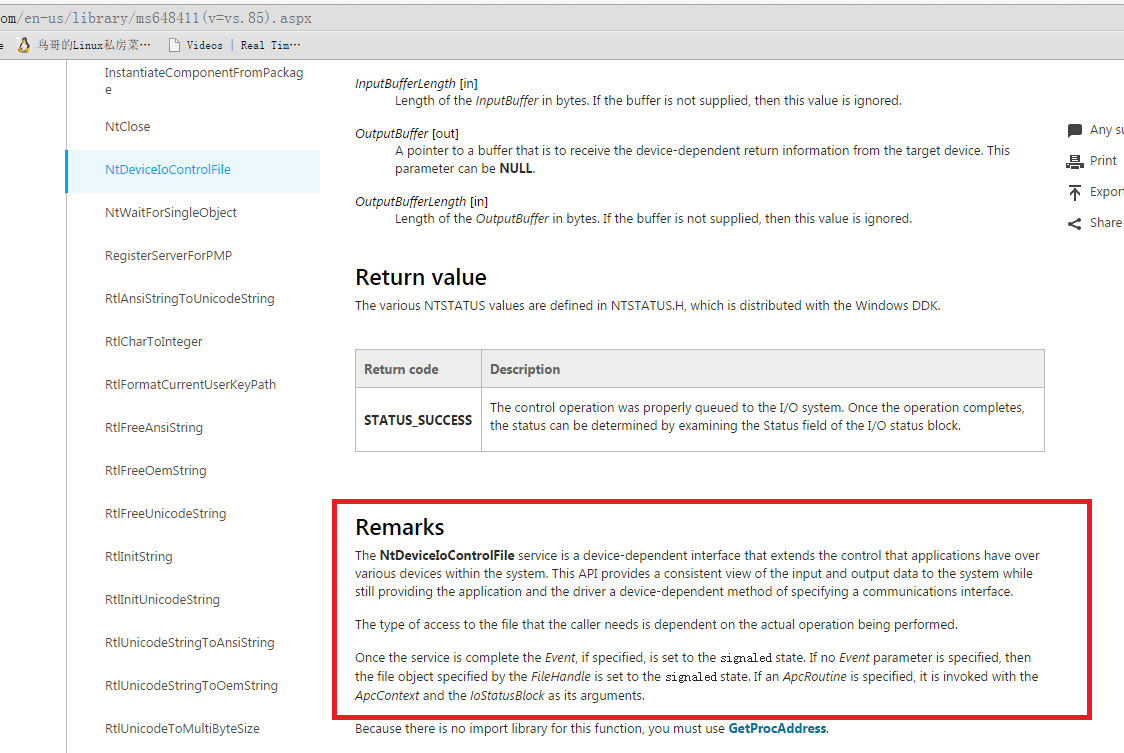
本来标题想取名成 《如何做好代码的性能优化》,但发现如果仅仅说代码性能优化的话就太狭义了。
最近一年一直在单线程框架的工程上写代码,阅读框架代码以后,不禁感叹道:“这个框架的设计者不仅是个高手,而且对windows相当了解,甚至借鉴了windows内核里面的一些设计元素。”
首先介绍一下我手里的这个框架:
1,总体来说,整个程序几乎就是单线程+异步(对于DNS解析、IO操作等一些耗时或难以异步的模块,会另启一个线程去执行和管理)。
2,在这个单线程框架中,所有的业务、网络协议栈、数据处理都在挂在这个单线程中去运行,并且绝大对数情况和业务下面都能够很好的运行。
3,模块间通讯采取模拟异步/同步事件、异步/同步消息的方式来完成
4,数据通讯很简单,直接用堆内存传递,用完立即释放。
5,定时器是最简单的“轮询”方式实现(并非真正轮询)
现在遇到一个比较严重的问题,就是在这个单线程模型中,由于开发的时候存在编码人技能层次不齐,以及任务力度控制不均匀。
导致开发一些功能在获得执行时间时,执行时间太长或没有及时的将任务中断并将执行时间让给其他任务执行。
这样的现象导致最严重的问题,自身流程过长,效率不一定高(如果还依赖其他模块的执行结果)。并且其他模块不能及时的拿到执行时间,并将执行结果及时反馈。进而引起血崩效应,导致部分要求时效性高的功能出现问题。
为了解决这类问题,就要做程序性能上的优化。这个问题上,一般采取的优化策略有几种:
1,代码级优化,就是通过各种技巧,将本来执行效率低的代码进行一点一点的修改并加快。这种优化方式周期长,效果不见得很明显,但对于长久来说是具备一定好处的;可以让优化者能够熟悉和了解整个代码的运行情况和流程等。
2,业务/功能优化,通过将长流程或者耗时的流程将功能和业务优化掉。然长流程变成短流程,然后进而增加执行时间在任务中的切换频率。可以促进轻量级任务的提早执行和结束,也间接能够提高大部分任务的及时性。但对于原本又长又臭的任务来说,此类优化可能带来的改善并不大,同时还需要优化者对程序整体有一定度的把握。
3,任务分拆,这样优化方式是将任务的关联性和时效性做一个定性分析。将相关任务集中起来,不相关任务分拆开;并将任务流中的上下游进行松耦,接着再对相关的业务进行松耦。这样做的好处在于一切以任务执行为视角,进行分拆,可以有效的区分开重任务和轻任务。同样也可以定性的了解到即使性要求高的任务和及时性要求低的任务。缺点在于,优化者同样也要对整个程序有一定的了解。
4,框架优化。这个难度大,没有做太大分析。
因为1和2都是夹杂着代码上技巧性的优化,这种优化如果考虑不当很有可能事倍功半,反而降低代码的可阅读性和可维护性。之前,我就遇到过一些成天嚷嚷着“算法”的人在用“算法”的思维去优化代码,结果代码优化下来性能是有一定的改善,但可维护性和可阅读性就差到极点了。甚至优化者本人自己去维度代码也是满天飞的bug。
介于4这种都是构架师水平,我最终选择3。
从任务的关联性出发,将一些重任务,以及及时性要求高的任务进行分类,并把这些任务的旁路任务进行一同整理。最终得到几类任务:
1,一般任务
2,及时性高任务
3,重任务
其中一般任务继续保留在原先的单线程框架中。及时性高的任务会从中剥离出来,并挂在一个新的单线程框架中;后期随着这个单线程任务量的增加,最终线程会逐步调整代码中的线程数。
重任务,其中重任务也被挂在一个新的单线程框架中,处理方式与及时性任务的处理方式一致。只不过对于及时性高的任务,可能还需要做一些代码层面上的执行优化,不过应该不多。
通过上面的方案进行优化了以后,发现整个客户端任务执行的拖沓、任务切换的不及时得到了较大的改善。看来改善任务安排有时候比起用一些代码技巧更为重要。
当然,我在这里说说是很容易的,实际写起代码来未必那么容易。因为涉及到多线程,就需要留意任务的关联性。因为关联性的存在,就会出现线程资源竞争,资源出现竞争时,就会很容易出现数据不同步,死锁,野指针等问题。
这是就需要经验和一定的代码技巧来解决这类问题。因此合理调整程序结构与代码技巧同样重要,如果一味的追求代码技巧和所谓的“算法”,那最终会失去对整个程序的可持续维护和开发的可能。这就如我之前所呆的一家公司一样,软件在国内某行业里还是有点小名气,但是真的要去看代码的话…………………bug、可阅读性不是在人类可理解范围内。反而这个团队内总有人一味的强调“算法”、“二叉树”什么的,数据结构与算法确实是程序的核心之一的东西,但现在国内的公司并非科研机构,顶多只能算一个做的工程。多数时候其实以工程的思维就能把问题解决好的,根本没有必要上升到“算法”层面,再说了,代码都没写好装什么逼呢?