因为不是做cuda相关开发,临时被拿来做调试一些相关代码。看到官方的一些介绍并不是很清晰,并没有完全说明cuda计算单元和nvenc/nvdec关系。仅仅提到nvenc和nvdec是两个编解码引擎。
并且还对特定显卡做了nvdec和nvenc的限制,对于一些老卡上,并没有nvdec和nvenc引擎。
官方给出的定义是nvdec、nvenc是独立于cuda核心,并不是很理解。或许nvdec和nvenc是相对于cuda核心的单纯的计算功能而划分出来给视频编解码使用的一个特定模块。
上网查了一下,以前的GPU加速编解码,实际上是利用cuda计算单元做一些数学计算,加快编解码速度。而nvenc和nvdec可以直接未编码数据或已编码数据进行处理。
那么这里就很好奇了,nvenc是一个单独的物理模块,还是一个逻辑模块。
通过对比实验发现还是稍有区别:
- 第一个实验,仅使用nvdec、nvenc,以及ffmpeg的混流滤镜。得到的数据如下:
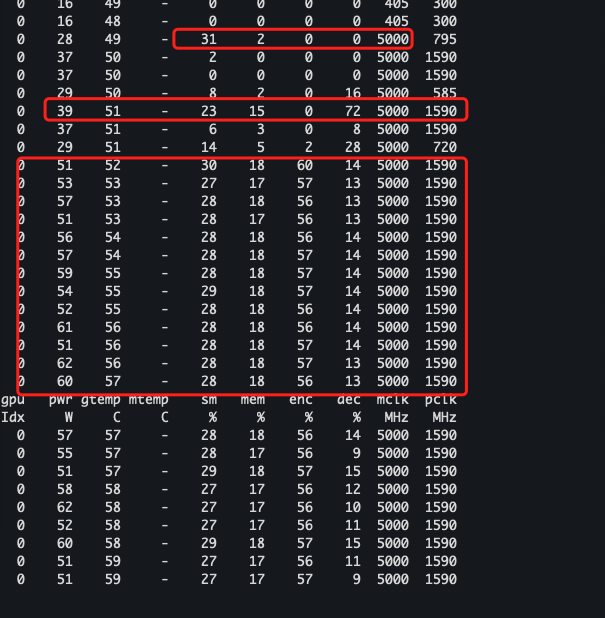
- 第二个实验,通过外部加载一个推理模型。将解码好的数据丢给推理模型进行推理后,再返回解码,所有的过程均在显存中进行。
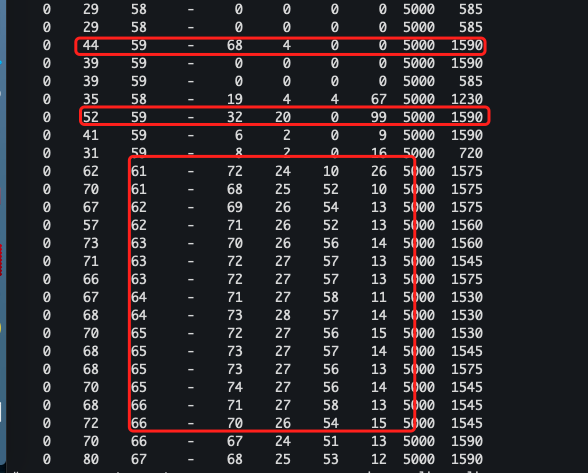
通过nvidia-smi dmon,可以发现除了流处理使用率有所增长,在程序初始化初期,从数据是上来看,可以推测nvenc和nvdec实际上还是利用到了部分流处理器,至于把这些流处理器拿来做什么就不得而知,也许只是作为解码初始化的一些树的加速计算,也许仅仅是被划分到nvenc、nvdec中参与编解码工作。
后续还需要一些相应深入和系统性的了解才好做判断。
用信号量来做共享内存的互斥操作,执行semop阻塞式调用。
结果发现执行p操作(加锁)会较低概率不定期的出现EINTR失败,查看linux手册,看到如下片段:

也就是当线程正在对信号量进行操作时,刚好出现该线程捕捉到了一个信号,这时候刚好接收到某个信号执行了相应信号的相应中断处理函数。
这主要是由于信号是以进程为单位,而具体某个信号会被进程内部的哪一个线程执行,这是极有可能不可预知的(主要有操作系统而定)。因此在这种情况下时,如果semop执行出现了一个EINTR错误,那么只需要再次重启调用semop就好。
解决这个问题的办法有两个:
1,通过屏蔽掉大部分该线程不关心的信号来解决,但是这样有可能会出现误屏蔽的操作情况。
2,单独开启一个线程来执行sigwait,作为信号处理线程。
前提条件
显卡类型:专业显卡
特征:具备内存ECC,和一些特定的纠错能力,其他暂时不清楚。
SRAM报ECC错误,导致申请显卡资源失败。
该问题是使用ffmpeg通过cuda api进行申请显卡资源出现报错,或出现长期卡顿不动的情况。出现该问题时,一般均为向驱动产生较高的并发请求,并伴随着相对高一些的负载情况下。
透过nvidia-smi可以看到相应错误为:
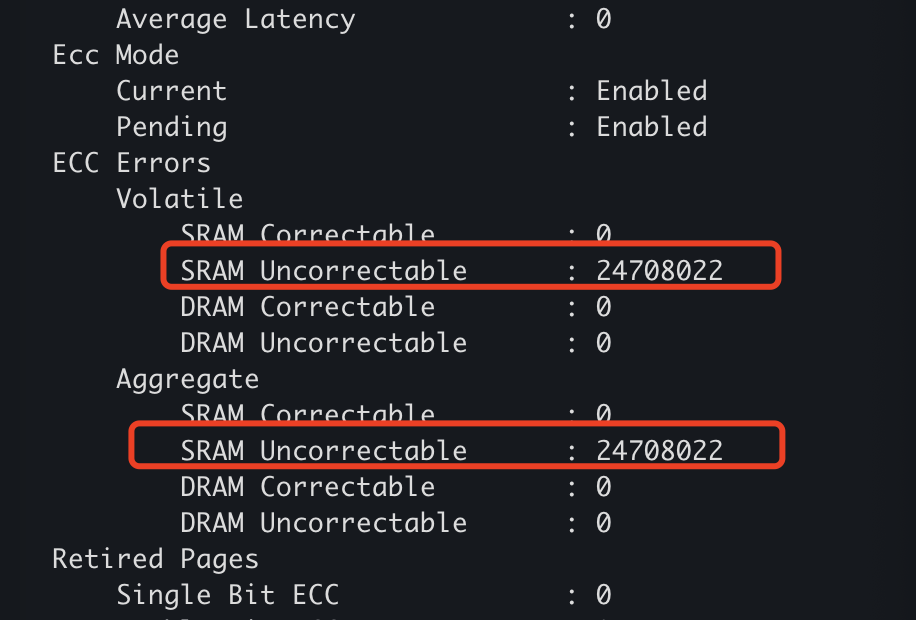
可以看到SRAM的错误计数器已经很大,并且是无法纠错的部分。sram又常常被用于寄存器,所以出现这类错误时,gpu状态已经出现异常了,且nvidia官方仅仅提供了显存页的重定向(“退休”),并没有相应寄存器的不可纠错异常处理,因此再这样的情况下时,只有通过重启硬件来尝试解决,并通过nvidia-smi重置显卡。
不过在官方的文档里,如果30天出现5次以上的SBE,基本就可以考虑返修。对于SRAM错误,估计也是离返修不远了,除非是纯vbios或其他软件部分的问题。
参考信息:https://docs.nvidia.com/deploy/dynamic-page-retirement/index.html
最近在做一些编解码相关的优化,以及前段时间隔壁同事在做一些机器学习相关的内容。
当时公司配了T4、V100、T100的卡。一直并不真正理解专业卡和消费级卡到底有什么区别,为何要买。
消费卡的渲染仅仅做表面,而专业卡会连同三维模型的内部也一同进行渲染,因此在相同流处理器数量一样的情况下时进行三维渲染时,消费卡输出图形数量会比专业卡极有可能更快,因为渲染步骤会少很多。
另外就是流处理个数不同,相同GPU核心大类的情况下,专业卡的流处理数量会比消费级更多。这些也仅限于之前的了解,包括gt8600时代的认知,因为后面的gpu核心架构变化比较大。
cuda单元:NVIDIA显卡的基本计算单元,这个实在硬件设计时已决定,但也不排除实际数量大于配置数量,故意做了屏蔽的情况,比如之前就出现过一些gtx显卡的gpu芯片中的cuda数明显大于该卡宣称数量,其中有些网上解释为工艺问题,导致较高端卡批次不合格,降级为低端卡卖。类似intel和amd cpu工艺不达标降级达标卖一样。
流处理器:single Instruction MultipleThread,SIMT,可以看做是若干个cuda单元组合成的一个逻辑处理器。nvidia-smi中的sm就是流处理使用率。这个的数量由驱动和硬件配置来决定。
显存:不解释。但专业卡普遍支持ecc,消费级要近几年高端卡才有。在做一些要求可靠性高的计算时,这个很关键。
nvenc:nvidia的编码引擎,非开源,按照官方的介绍,这是由驱动+cuda构成,但网上又说这个也有独立的硬件模块存在。没有做过深入了解。
nvdec:nvidia的解码引擎,和nvenc类似。
cuvid:nvdec旧名,但不清楚两者真实的差别。
浮点数:这个在gpu上很受关注的问题,由于编解码,机器学习都需要用到。所以gpu在渐渐把支持的越来越好。
定点数:起初gpu做浮点数模拟的时候性能太差,导致性能比较差,因此之前的都是采用定点数来计算小数问题。精度丢失相对严重,导致编码出数据和计算结果有较大的误差。现阶段由于编码器算法的改进,这块失真在逐渐减小,以及浮点数的支持,也相对好很多。不过在机器学习上,还是很突出这块问题。
如果是做机器学习相关,可能在cuda数量方面会需要比较关注,同时还需要关注显存大小,据说模型加载也很耗显存。这块没做太多深入了解
如果是做视频编解码加速,那么需要关注nvenc和nvdec配置的数量,不同的卡配置数量不同。一般nvdec只有一个,nvenc会有大于一个的情况。同时nvdec和nvenc的能力也会不同,主要体现在支持的颜色空间,支持的编码参数等。
另外就是显存大小也要重点关注,一些分辨率和编码参数下,显存会成为一个比较主要的瓶颈。