最近由于项目需要,需要解决在强交互中,音视频延时、同步问题。
1,了解了一下AAC编码的特点,通过查阅得知,一个AAC的压缩包是由1024个压缩前的PCM样本构成。换句话说,AAC对样本数的要求较高,带来的是AAC需要才待编码缓存中存储大量的样本,才能进行编码。如果按照44khz采样计算,1024个样本大约是1/44/1000*1000*1024=23ms;即,每个AAC包携带了23ms,如果不计算AAC数据包交付时隙的话,那么理想情况下,AAC编码器每次对外部输出数据的间隔是23ms,这23ms就是编码延时。
2,例如在普通的商业网络中(非专线,ADSL),用户到服务器之间的双向延时100ms(32个字节)。那么即可得出,样本的理想情况下的最大延迟在23ms+50ms=73ms。
3,实际上在目前绝大部分直播组网里面,基本可以简化成下图:
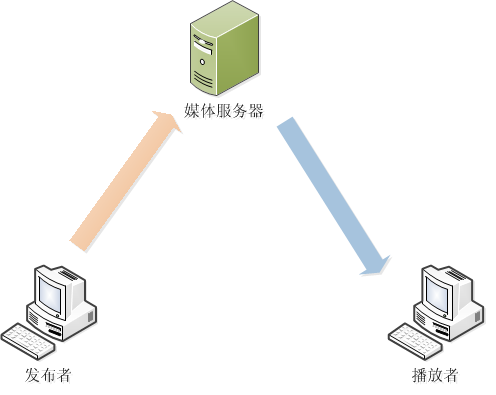
通过延时计算,可以得知,服务器得到的第一个音频样本其实已经是过时了的,并且已经过时了73ms。当服务器对数据再次转发给播放者时,延时将会被加大到123ms。这都还不考虑其他因素引起的延时问题。
4,由此可以得出,对AAC来说,本身就存在固有的23ms延时,加上网络的一个基准延时后,整体延时被放大到123ms,如果加上客户端、服务器之间的性能考虑,那延时或许可以达到200ms-300ms。
在双向通讯,即强交互中可以做如下初步估计:
a) 模型:A <—–> 服务器 <—–> B
b) 理想情况下,A说一句话,这句话经过了123ms后,B收到。
c) 不考虑解码延时等问题的情况下,B回复A说的这句话。再次经过123ms,A收到(此时A已经等待了大约123*2=246ms)。
经过简易的测试发现,在强交互中,人对延时的感知基本在300ms-500ms这个区间,按照个体素质不同,会存在一定的浮动;人对延迟的基本容忍,保持在3s左右。
所以可以得知,AAC方式的音频编码,在普通的商业互联网中进行直播交互是不适用的。